

Meta AI Research, FAIR
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4015-4026, 2023.
Introduction
Motivation
- Reducing the need for task-specific modeling expertise, training compute, and custom data annotation for image segmentation.
- Build a foundation model for object segmentation.
Objective
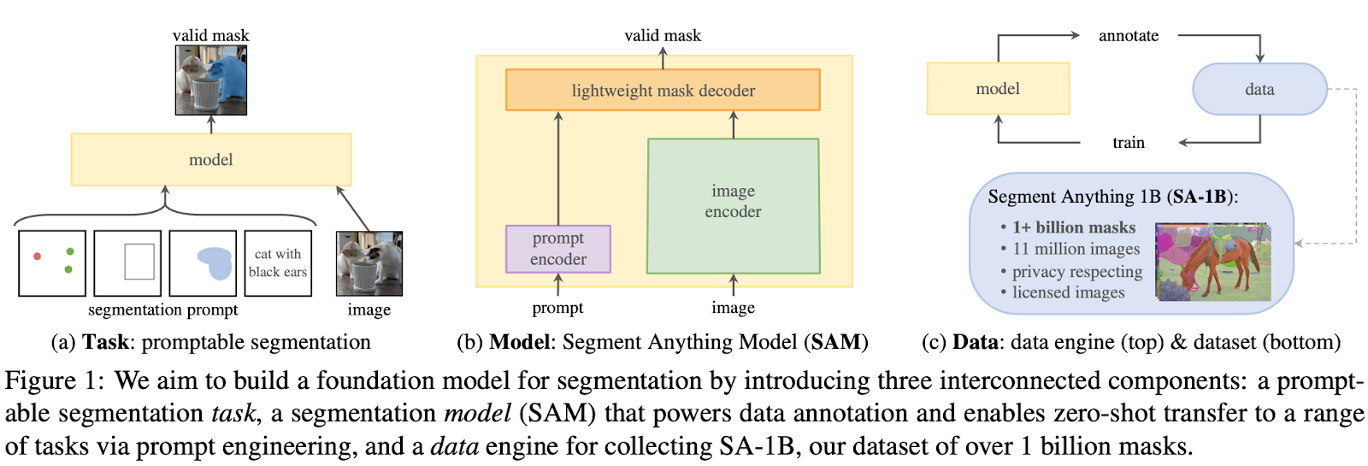
Segment Anything (SAM) = Interactive Segmentation + Automatic Segmentation
Segment Anything: Simultaneously develop a general, promptable segmentation model and use it to create a segmentation dataset of unprecedented scale.
- SAM allows users to interactively segment objects (click, bounding box, text) and output multiple valid masks.
- SAM can automatically find and mask all objects in an image.
- SAM can generate a segmentation mask for any prompt in real time after precomputing the image embedding, allowing for real-time interaction with the model.
Related Works
Foundation Models
- Models aligning paired text and images: CLIP [82] (contrastive language-image pretraining) and ALIGN [55] (use contrastive learning to train text and image encoders that align the two modalities).
- Model generate images: DALL-E [83]
Dataset
- [66, 44, 117, 60]
Framework
Segment Anything (SAM) has three components:
- An image encoder produces a one-time embedding for the image.
- A prompt encoder converts any prompt into an embedding vector in real-time.
- These two information sources are then combined in a lightweight decoder that predicts segmentation masks.
Contribution
Task: Promptable Segmentation Task – return a valid segmentation mask given any segmentation prompt.
Model: Segment Anything (SAM)
Data Engine: Co-develop the model with model-in-the-loop dataset annotation.
- Assisted-manual.
- Semi-automatic.
- Fully automatic.
Dataset: SA-1B, 1B masks from 11 licensed and privacy-preserving images.
Details
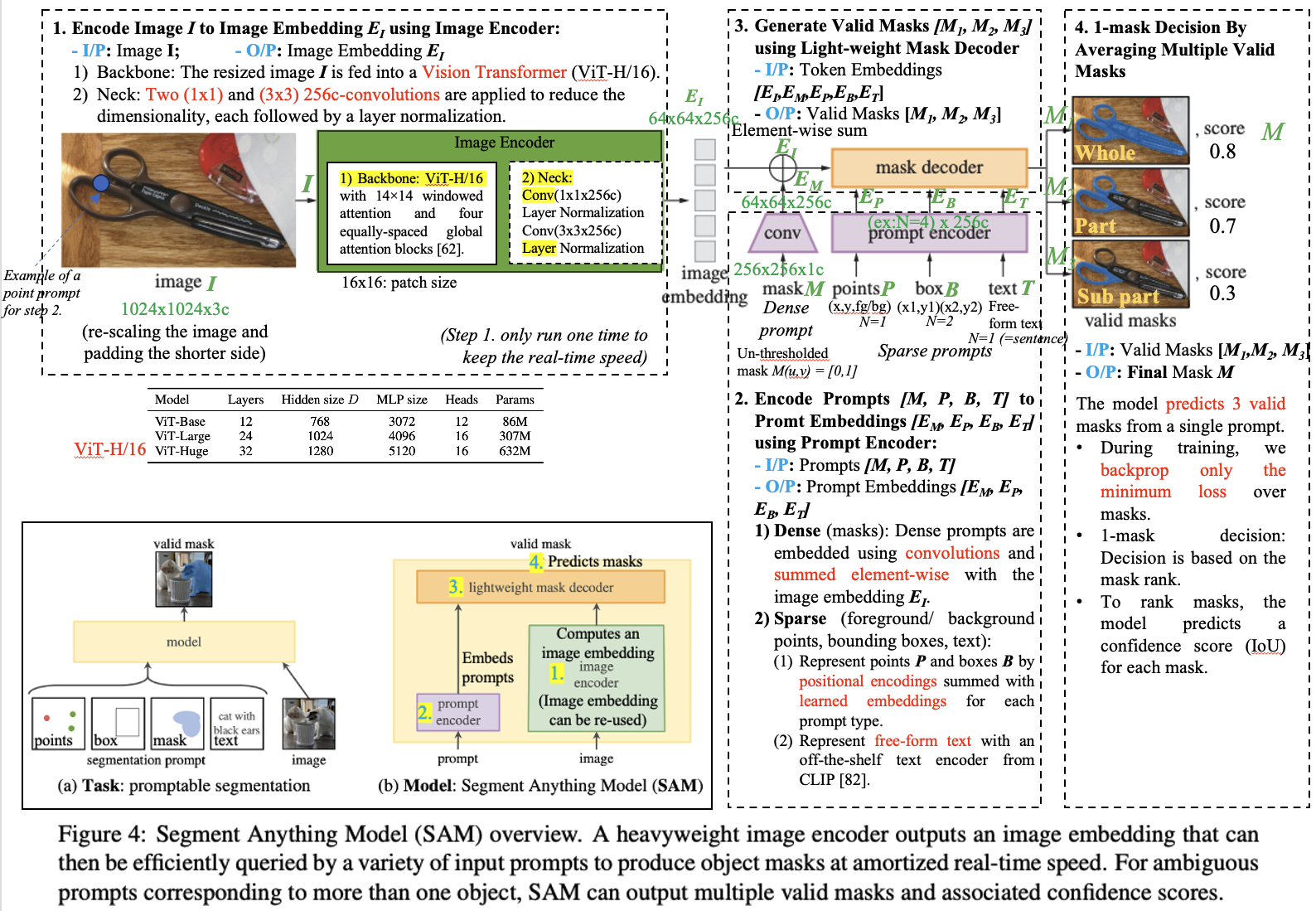
Image Encoder
The image encoder’s job is to process a high-resolution image and convert it into a smaller, feature-rich embedding. A key feature is its efficiency: the encoder runs just once per image, and its output can be reused for any number of different prompts.
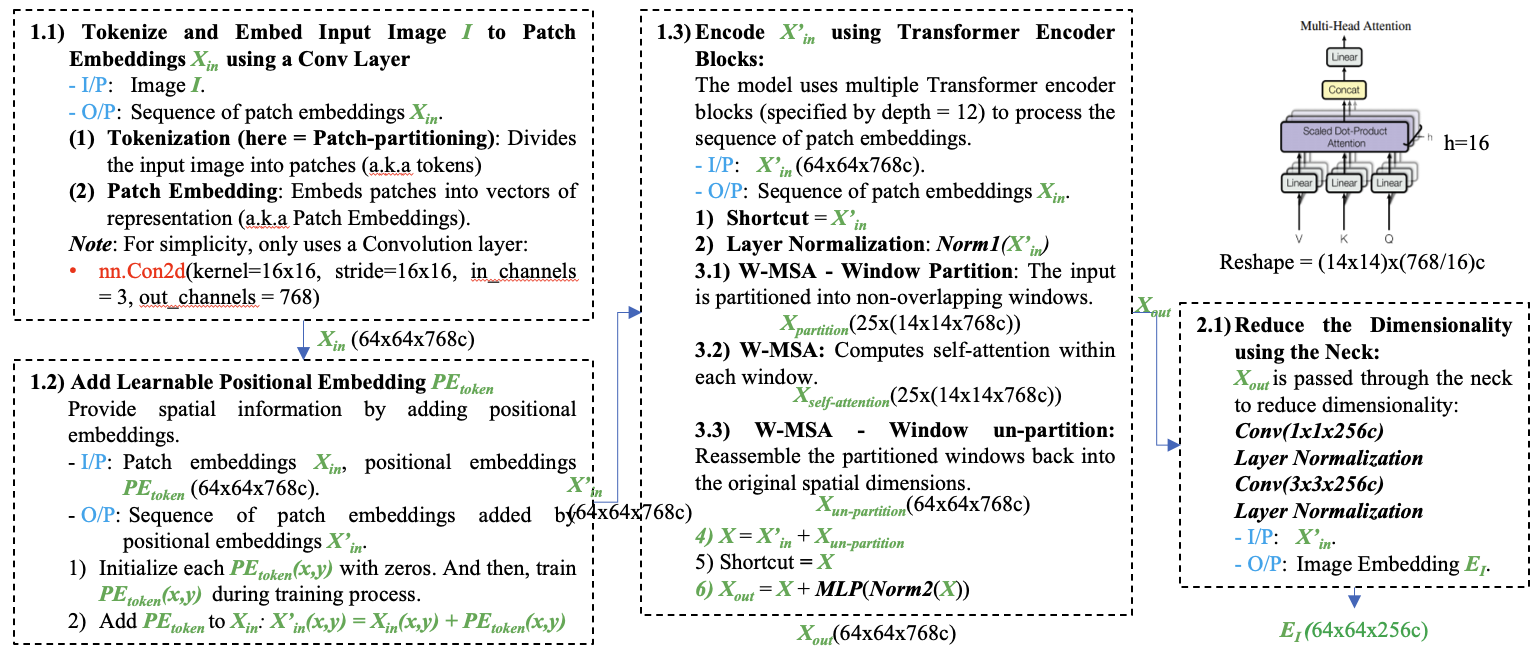
Input: The model receives an input resolution I of 1024×1024 pixels, obtained by rescaling the image and padding the shorter side.
Steps:
- Vision Transformer (ViT): The core of the encoder is a large, pre-trained Vision Transformer (specifically, a ViT-H/16). This powerful model is responsible for “understanding” the input image and extracting its complex visual features.
- Channel Reduction: Two convolutional layers refine the ViT’s output. A
1x1convolution followed by a3x3convolution reduces the feature map to the final 256 channel dimension.
Output: A 16×downscaled embedding EI of the input image (ex: 64×64x256c), capturing the essential information of the image in a compact format ready for the mask decoder.
Prompt Encoder
Dense Prompt
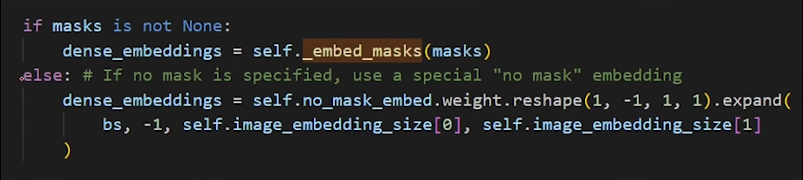
A dense prompt is an input mask, which provides detailed, pixel-level guidance that has a direct spatial correspondence with the image. If no mask is provided, a special learned embedding signifying “no mask” is used instead.
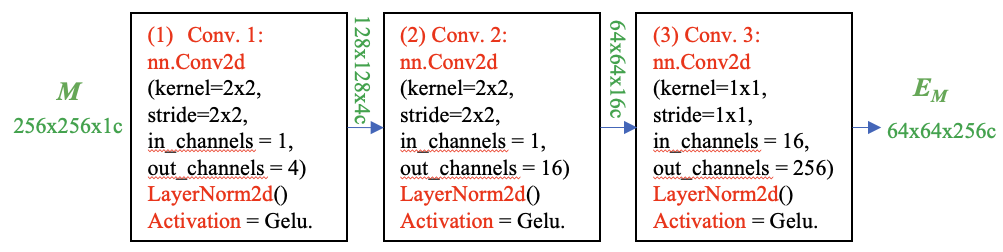
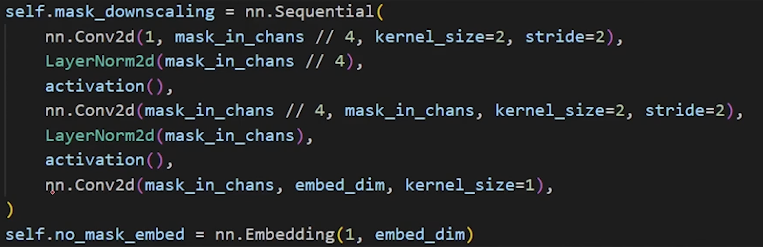
Input: Mask M at a 4× lower resolution than the input image,
Steps:
- Downscale an additional 4× using two 2×2, stride-2 convolutions with output channels 4 and 16, respectively.
- A final 1×1 convolution maps the channel dimension to 256.
- Each layer is separated by GELU activations [50] and layer normalization.
Output: A dense mask embedding EM.
The mask embedding EM is then added element-wise with the image embedding EI. This directly infuses the image’s feature map with the detailed spatial information from the input mask before it’s processed by the decoder.


Sparse Prompt
The prompt encoder converts various user inputs, known as sparse prompts, into a standardized format the model can understand: 256-dimensional vector embeddings. It can process multiple prompts at once.
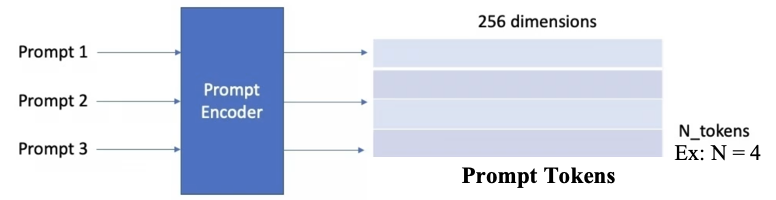
Input: User prompts – Point (positive or negative), Box or Text.
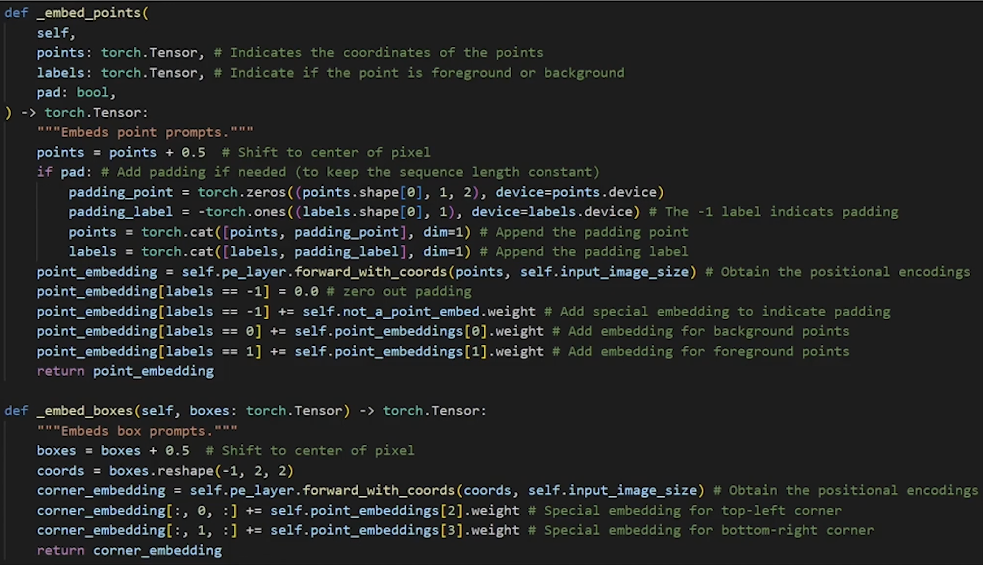
Point Prompts:
- A single point is encoded by summing two vectors:
- A positional encoding of the point’s
(x, y)coordinates. - A learned embedding that indicates the point’s role as either foreground (part of the desired object) or background.
- A positional encoding of the point’s
- This allows the model to know both where the point is and what it signifies.

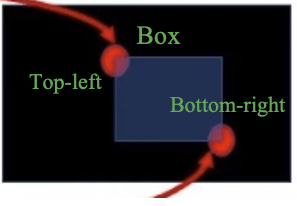
Box Prompts:
- A bounding box is represented by a pair of embeddings, one for each of the two corners that define it:
- The top-left corner’s embedding is the sum of its coordinate’s positional encoding and a learned embedding that specifically marks it as “top-left.”
- The bottom-right corner’s embedding is created the same way, using its own coordinates and a “bottom-right” embedding.
- This embedding pair gives the model a precise representation of the box’s location and extent.
Text Prompts:
- To understand free-form text prompts, the model uses a pre-trained text encoder from CLIP. This component converts the text into a rich vector embedding that captures its semantic meaning.
- While CLIP is the standard choice, the model’s design is flexible enough to accommodate other text encoders.
Mask Decoder
The decoder’s main function is to interpret the image’s features and the user’s prompts to generate a precise object mask.
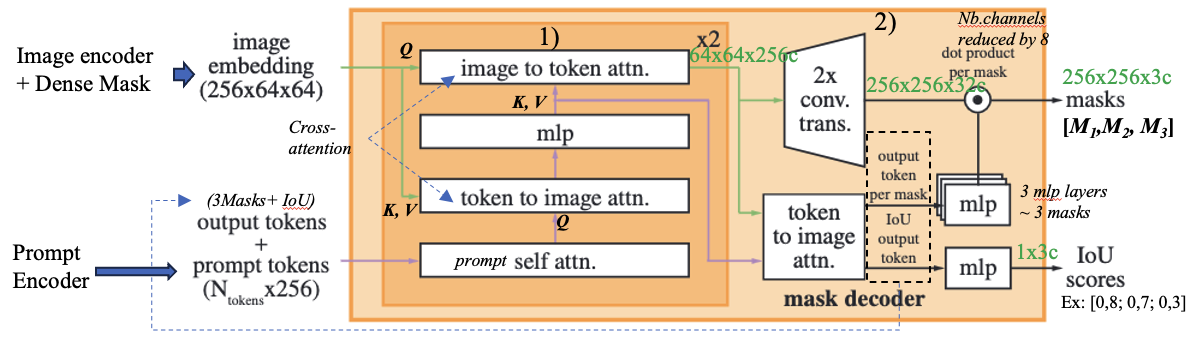
Input:
- An image embedding from the image encoder.
- A set of prompt tokens, which are embeddings representing user inputs like points, boxes, or text. A special, learnable output token is added to this set, which will ultimately be used to generate the mask.

Steps:
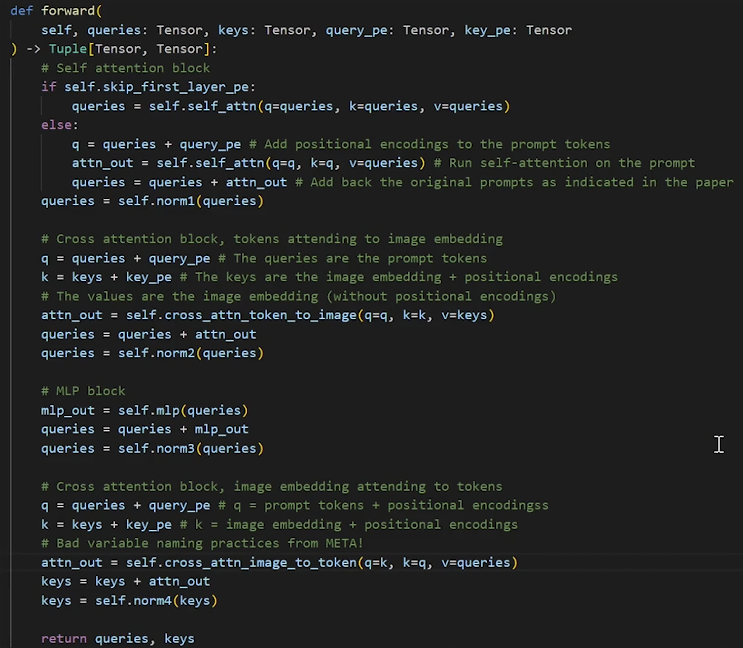
- Two-Layer Decoder Block: The core of the decoder is a transformer block that is applied twice. Each pass through this block refines both the prompt tokens and the image embedding. A single decoder layer consists of four key steps:
- Token Self-Attention: The tokens (including prompt tokens and output tokens) attend to each other. This allows them to build a richer contextual understanding among themselves.
- Cross-Attention (Tokens to Image): The prompt tokens act as queries to “look at” the image embedding. This step allows the prompts to gather the most relevant visual information from the entire image.
- Point-wise MLP: A Multi-Layer Perceptron (MLP) processes each token embedding individually. This adds computational depth, allowing the model to process the information gathered during the cross-attention step.
- Cross-Attention (Image to Tokens): In a reverse attention mechanism, the image embedding acts as the query to attend to the prompt tokens. This crucial step updates the entire image embedding, making it aware of the specific object being requested by the prompts.
- To preserve crucial location data, positional encodings are added to the image embedding and prompt tokens before they enter any attention layer.
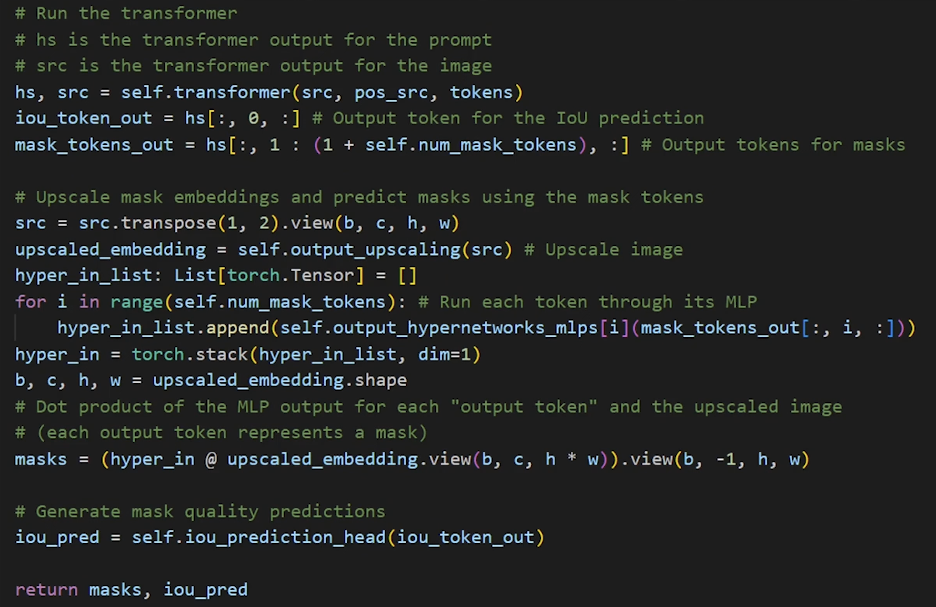
- Final Mask Generation: After passing through the two decoder layers, the updated embeddings are used to produce the final mask.
- Upsampling the Image Embedding: The refined image embedding (64×64) is upscaled by a factor of 4× to a size of 256×256. This is done using two transposed convolutional layers. This brings the embedding to a higher resolution, just 4x smaller than the original input image.
- Final Attention and MLP: The updated output token attends one last time to this upscaled image embedding. This final output token is then passed through a small 3-layer MLP. The purpose of this MLP is to transform the token embedding into a new vector that has the same channel dimension as the upscaled image embedding.
- Dot Product: The final mask is created by performing a simple dot product between the upscaled image embedding and the vector produced by the MLP. This operation is computationally efficient and generates the final binary mask for the targeted object.
- IoU Score Prediction:
- In parallel with mask generation, the model also predicts the quality of the generated mask. As seen in the diagram, the updated output token is also fed into a separate MLP, which outputs a single value representing the predicted Intersection over Union (IoU) score.
- This score indicates the model’s confidence in the accuracy of its own output mask.
Making the Model Ambiguity-aware
A single prompt can be ambiguous—a click on a person’s shirt could refer to the shirt, the person, or a logo on the shirt. Instead of outputting a blurry average, the Segment Anything Model is designed to resolve this ambiguity by producing multiple valid mask options.

Handling a Single, Ambiguous Prompt
When the model receives a single, potentially ambiguous prompt, its strategy is to provide a few distinct possibilities.
- Multiple Outputs: The model predicts three different masks simultaneously. This often captures objects at different levels of detail, such as a “whole” object, a “part” of it, and a “subpart.”
- Smart Training: During training, all three predicted masks are compared against the ground truth. However, the model only learns from the best one—it backpropagates the loss from the single prediction with the lowest error. This encourages the model to produce diverse and high-quality options.
- Ranking Masks: To help users select the best mask, the model also predicts a confidence score (an estimated IoU) for each of the three masks.
Handling Multiple, Unambiguous Prompts
When a user provides multiple prompts (e.g., several points), the ambiguity usually vanishes. The model adapts its strategy to be more efficient in these clear-cut cases.
- The Switch: When more than one prompt is given, the model predicts only a single, confident mask instead of three. This avoids the redundancy of producing three identical outputs for an unambiguous request.
- Implementation: This is achieved using a dedicated fourth output token.
- For a single prompt, the model returns the three masks described above.
- For multiple prompts, the model returns only the single mask generated by this special fourth token, ensuring a clean and direct result.
Loss Function
The Segment Anything Model is trained using a composite loss function, with different components designed to optimize mask accuracy and predict mask quality.
- Lmask: Supervise mask prediction with a linear combination of focal loss [65] and dice loss [73] in a 20:1 ratio of focal loss to dice loss.
- LIoU: The IoU prediction head is trained with mean-square-error loss between the IoU prediction and the predicted mask’s IoU with the ground truth mask. It is added to the mask loss with a constant scaling factor of 1.0.



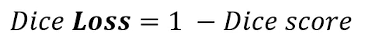
Data Collection
Data Engine
The dataset for the Segment Anything Model (SAM), called SA-1B, was created using the model itself in a powerful feedback loop called the “data engine.” This process was highly efficient, with human annotators taking only about 14 seconds to interactively create a high-quality mask. The engine had three distinct stages.
Stage 1: Assisted Manual Annotation
This initial stage was a human-in-the-loop cycle designed to iteratively improve both the model and the dataset.
- Annotate: Human annotators used an early version of SAM to interactively label masks on images.
- Retrain: This newly annotated data was immediately used to retrain and update the SAM model.
- Repeat: This cycle was repeated many times. As the model improved, it became a better tool for annotators, accelerating the process. During this phase, the model’s image encoder was upgraded from ViT-B to the more powerful ViT-H.
Stage 2: Semi-Automatic Annotation
The goal of the second stage was to increase the diversity of the masks in the dataset. This involved a mix of automated and manual annotation. While the model automatically labeled objects it was confident about, human annotators were specifically tasked with finding and labeling objects and categories that the model was still missing. This targeted approach ensured the dataset’s variety continued to grow.
Stage 3: Fully Automatic Annotation
The final stage was designed for massive scaling. To generate the bulk of the 1.1 billion masks, the process was fully automated:
- Prompting: For each image, a
32x32grid of points was used as prompts for SAM. - Predicting: The model generated a set of potential masks for each point prompt.
- Filtering: The model’s own IoU prediction module was used to automatically identify and keep only the masks it was confident in.
- Cleaning: Non-Maximal Suppression (NMS) was used to filter out and discard redundant, highly overlapping masks.
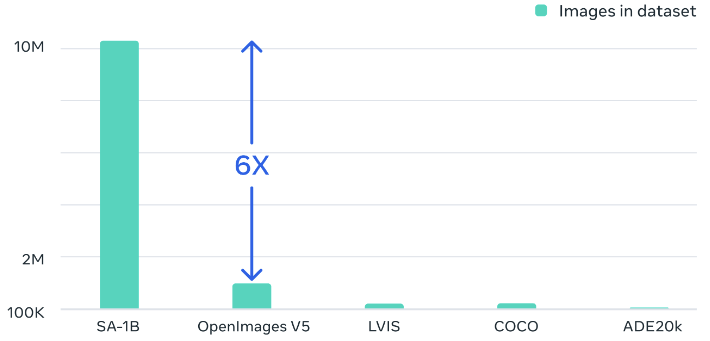
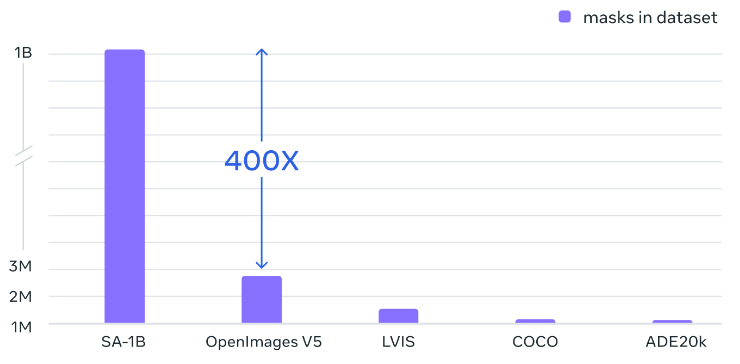
Dataset
SA-1B dataset contains 1.1 billion segmentation masks collected from approximately 11 million licensed, privacy-preserving images.
Experimental Results
SAM’s performance was evaluated against specialized models on several tasks, showcasing its versatility:
- Single-Point Segmentation: It was compared to interactive segmentation models like RITM and SimpleClick.
- Edge Detection: It was evaluated against the specialized EDETR model.
- Object Proposals & Instance Segmentation: Its capabilities were measured against the state-of-the-art ViTDet-H.
- Text-to-Mask: It was compared against the RIT model for segmenting objects from text descriptions.
In all cases, SAM performed these tasks “zero-shot,” meaning it was applied directly without any fine-tuning on the target datasets.
Conclusion
- SAM achieves strong zero-shot performance on diverse segmentation tasks by combining a powerful image encoder with a promptable interface and massive dataset.
- SAM’s flexible design positions it as a foundation model for numerous applications, with potential extending beyond computer vision.
- Future work includes enhancing SAM’s capabilities in complex scenes, prompt engineering, and 3D segmentation.
Reference
- Learnable Fourier Features for Multi-Dimensional Spatial Positional Encoding
- Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
- https://segment-anything.com/
- https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
- Train on Custom Dataset: https://encord.com/blog/learn-how-to-fine-tune-the-segment-anything-model-sam/
- Segment Anything – Model explanation with code

Leave a Reply