

Stanford CS25: V5 I Overview of Transformers
This lecture provides a comprehensive overview of Transformers, from the foundational concepts to the latest advancements and future challenges.
https://www.youtube.com/watch?v=JKbtWimlzAE&list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM&index=34
Fundamental Knowledge of Transformers
- Word Embeddings = converting words into dense vectors in a high-dimensional space to be processed by models.
- Semantic similarity: “king” – “man” + “women” – “queen”.
- Methods: Word2Vec, GloVe, FastTex.
- These static embeddings have limitations (since a word has only one vector, the model can’t differentiate its meaning in different sentences. For example, “I went to the river bank” and “I need to go to the bank to deposit money”).
- ==> Contextual embedding solves the problem (used in models like BERT and GPT, where the vector for a word is dynamically generated based on the specific sentence it’s in).
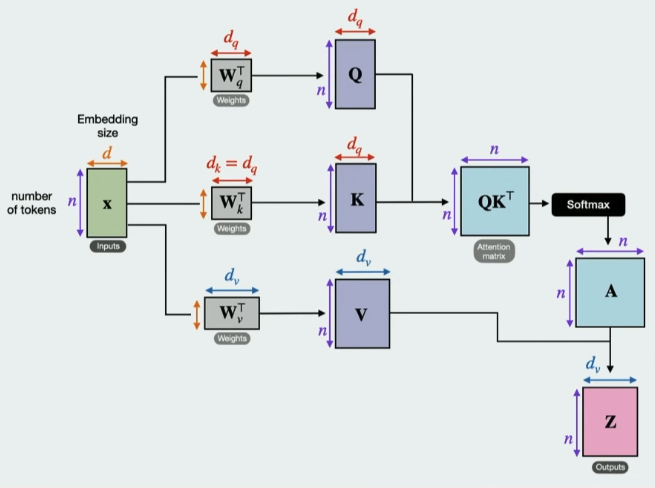
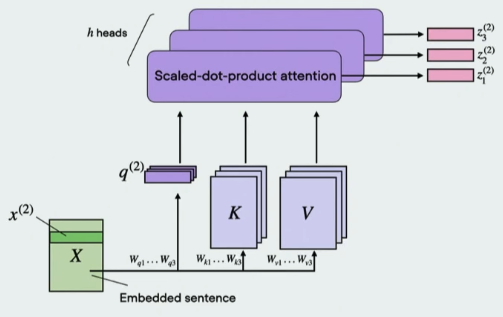
- Self-Attention: The core mechanism of Transformers. It learns what to focus on for each token (words broken up).
- Query Q: current word you’re focusing on (like a specific question or search term)
- Key K: a label or a summary for each word in a sentence. It’s the key that the query is compared against to find a match.
- Value V: contains the actual content or meaning of a word. Once the Query and Key have been matched to determine the relevance, the Value vector is what’s actually used in the final output.
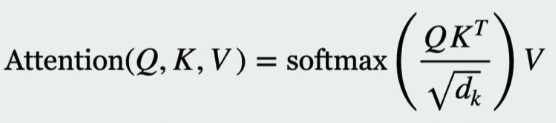
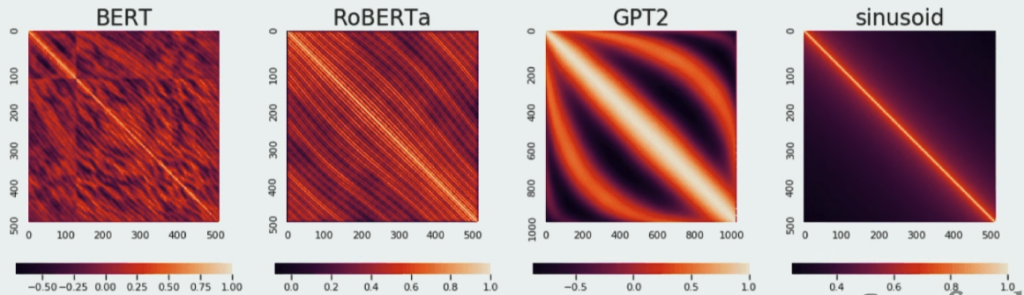
- Positional Encodings: To address the order-agnostic nature of self-attention, positional encodings are added to provide information about the position of each word in the sequence.
- Scaling Up: The lecture explains how scaling up the Transformer architecture with multiple layers and attention heads enables the model to capture more complex relationships in the data, leading to the development of Large Language Models (LLMs).
- Tranformers today:
- LLMs: GPT-4o, DeepSeek, Claude, Gemini, Llama…
- Vision: CLIP, Segment Anything, DINOv2.
- Speech: Whisper, Voicebox.
- Biology: AlphaFold-3
- Video: Sora, runway, pika.
- Robotics: RT-2, Code as Policies.
Pre-training and Data Strategies
- The Importance of Data: Data is the “fundamental fuel” for LLMs, and smart data strategies are crucial for effective pre-training.
- Small-Scale vs. Large-Scale Learning: Two research projects are presented to illustrate different data strategies.
- Project 1: explores whether child-directed speech is effective for training smaller models.
- Project 2: investigates a two-phase training approach with Optimal Data Blending for large-scale models.
- Key Takeaways: The research suggests that diverse data sources are more beneficial for language models than specialized data and that a structured, phased approach to pre-training can significantly improve performance.
Post-training and Fine-tuning
- Adapting to Specific Tasks: After pre-training, models need to be adapted to specific tasks. The lecture covers various post-training strategies, including:
- Prompt-based methods: Techniques like Chain-of-Thought, Tree-of-Thought, and Program-of-Thought are discussed as ways to guide the model’s reasoning process.
- Reinforcement Learning with Human Feedback (RLHF): This popular method involves training a reward model based on human preferences to fine-tune the LLM. The lecture also touches upon variations like DPO, RLAIF, and KTO.
- Self-improving AI agents: The concept of AI agents that can reflect on their own outputs and improve over time is introduced, with techniques like refinement, self-reflection, and the ReAct framework.
Applications Beyond Language
- Vision Transformers (ViTs): The lecture explains how Transformers have been successfully applied to computer vision by treating image patches as a sequence. This has led to the development of powerful models like CLIP and other vision-language models.
- Neuroscience: The application of ViTs to fMRI data is presented as a way to better understand brain activity and diagnose diseases like Parkinson’s.
Future of Transformers and AI
- Remaining Challenges: The lecture concludes by highlighting the key challenges and future directions for Transformers and AI, including:
- Efficiency: The need for smaller, more efficient models that can run on local devices.
- Interpretability: The importance of understanding the inner workings of these “black-box” models.
- Scaling Laws: The diminishing returns of simply scaling up models and the need for new architectures and training methods.
- Continual Learning: The challenge of creating AI systems that can continuously learn and adapt after deployment, similar to humans.
- Ethical Considerations: The importance of addressing issues like bias, safety, and value alignment.

Leave a Reply