

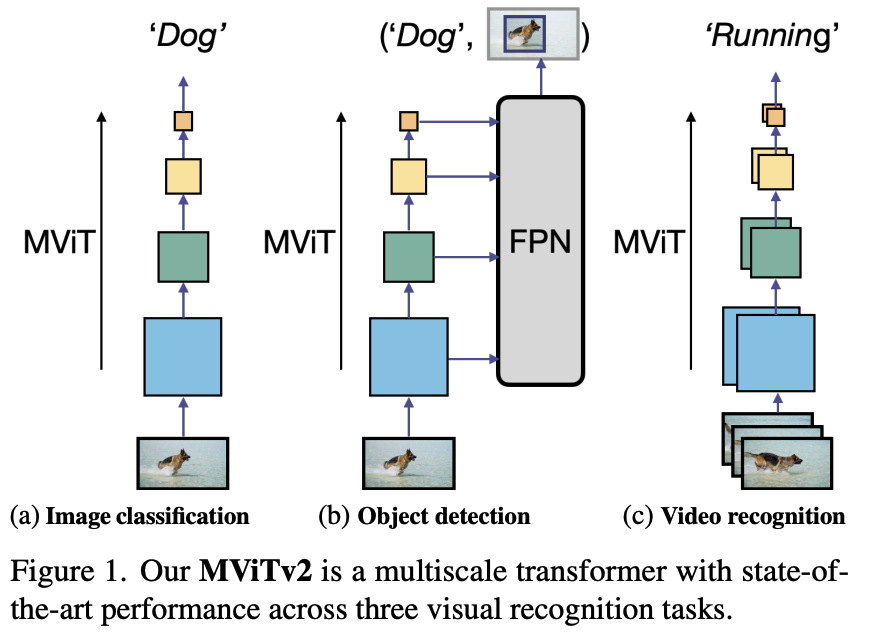
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
Facebook AI Research, UC Berkeley
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
Introduction
Motivation
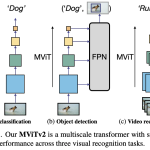
Designing a single, simple, yet effective architecture for diverse visual recognition tasks (image, video, detection).
While Vision Transformers (ViT) are powerful, their standard architecture struggles with the high computational cost associated with high-resolution inputs required for tasks like object detection and video analysis.
objective
MViT2, an improved version of MViT, incorporates (1) decomposed relative positional embeddings and (2) residual pooling connections.
The paper instantiates MViTv2 in five sizes (Tiny to Huge)
Related works
- CNNs & ViTs: Convolutional Neural Networks (CNNs) have traditionally been the primary backbones for computer vision. The recent success of ViT has sparked widespread interest in transformer-based models for vision.
- Addressing ViT Complexity: The quadratic complexity of self-attention is a major hurdle for dense prediction tasks. Two popular strategies to mitigate this are:
- Window Attention: Limiting self-attention to local, non-overlapping windows (e.g., Swin Transformer).
- Pooling Attention: Downsampling key and value tensors before the attention operation to reduce sequence length (e.g., MViTv1).
global framework
MViTv2 is a hierarchical transformer that creates a multi-scale feature pyramid by progressively increasing channel width while reducing spatial resolution from input to output.
contributions
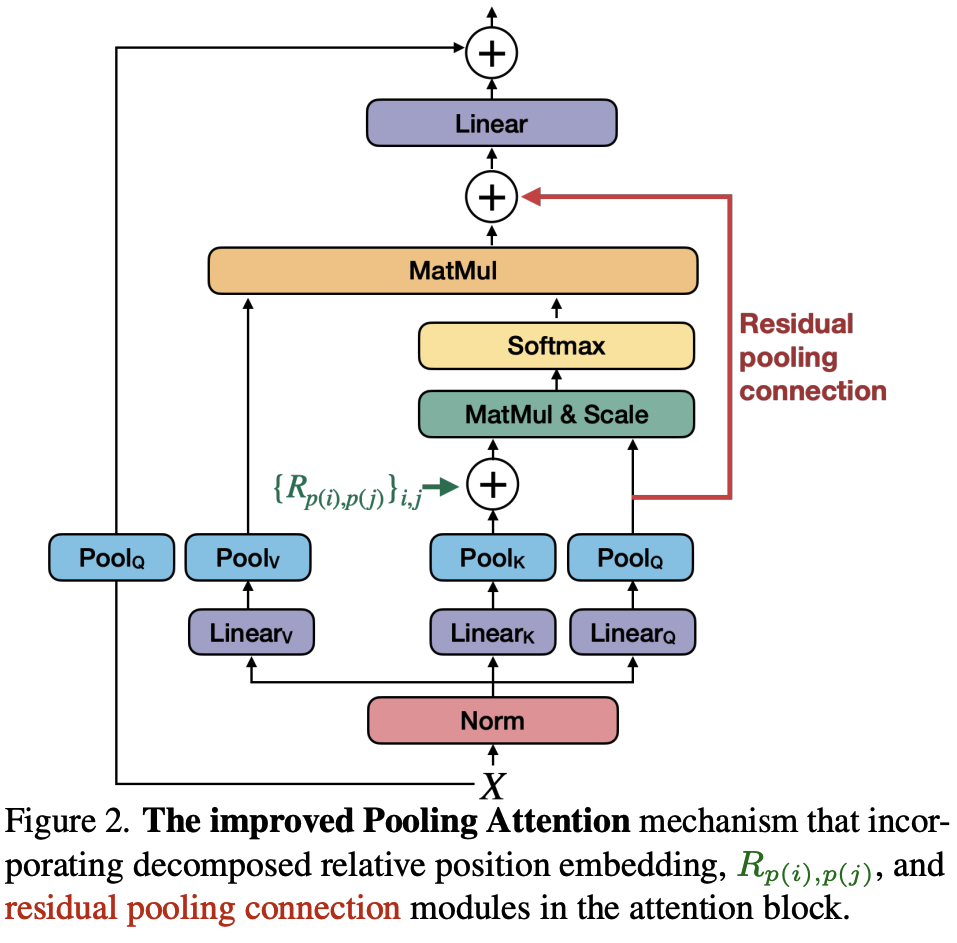
Improved Pooling Attention with two key technical upgrades:
- Decomposed Relative Positional Embeddings: Incorporates shift-invariance by adding relative position information in a computationally efficient, decomposed manner.
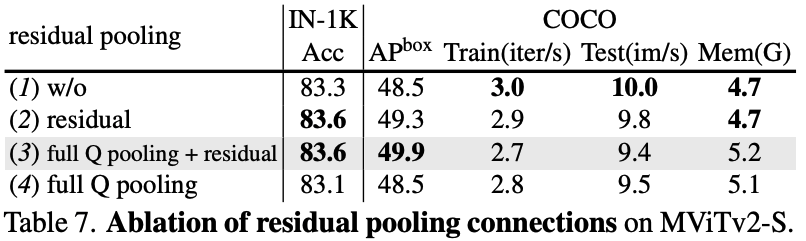
- Residual Pooling Connection: A skip connection is added from the pooled query to the output, enhancing information flow and stabilizing training.
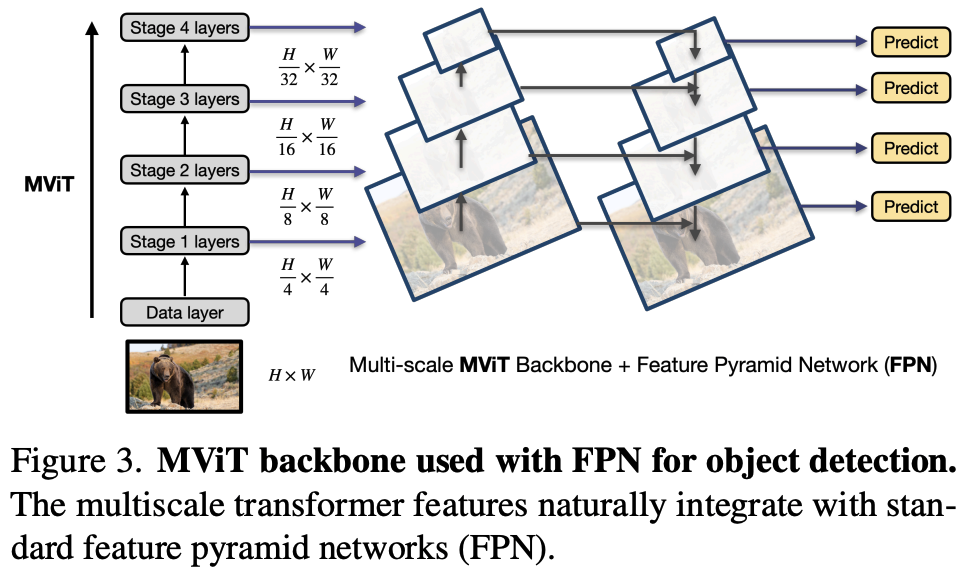
A Unified Backbone for Detection: The study demonstrates how to effectively apply MViTv2 to object detection using standard Feature Pyramid Networks (FPN). It empirically shows that pooling attention is a more effective and efficient mechanism than window-based attention for this task.
A new Hybrid Window Attention (Hwin) is also proposed as a complementary technique.
Details
Improved Pooling Attention
Decomposed Relative Positional Embeddings
Problem: The standard MViT relies on “absolute” positional embeddings, which ignores the principle of shift-invariance in vision. This means the model’s understanding of the interaction between two image patches changes based on their absolute position, even if their relative position is the same.
Solution: To solve this, the authors incorporate relative positional embeddings, which depend only on the relative distance between tokens. However, a naive implementation is computationally expensive, with the number of embeddings scaling in the order of O(TWH).
Decomposition Method: To reduce this complexity, the model decomposes the distance calculation along the spatiotemporal axes (height, width, and time). The final embedding is the sum of the embeddings for each axis:
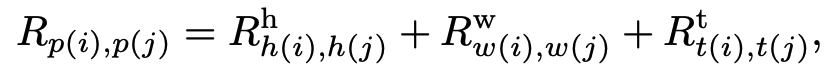
where:
Rhis the positional embedding along the height axis.Rwis the positional embedding along the width axis.Rtis the positional embedding along the temporal axis, which is only used for video tasks.
This reduces the number of required embeddings to O(T+W+H), which is much more efficient, especially for high-resolution feature maps. The temporal embedding (Rt) is optional and only used for video tasks.
Residual Pooling Connection
Motivation: In the original MViT, the key and value tensors have larger pooling strides than the query tensor. This inspired the addition of a residual connection with the pooled query (Q) tensor to improve information flow and aid in training the attention blocks.
Implementation: A new residual connection is introduced inside the attention block by adding the pooled query tensor directly to the output sequence Z. The equation is updated to
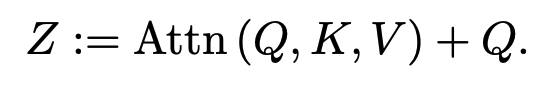
Benefit: This addition comes at a low computational cost, allowing the model to maintain the benefits of low-complexity attention computation while improving performance. The output sequence Z has the same length as the pooled query tensor Q.
MVIT for Object Detection & Video
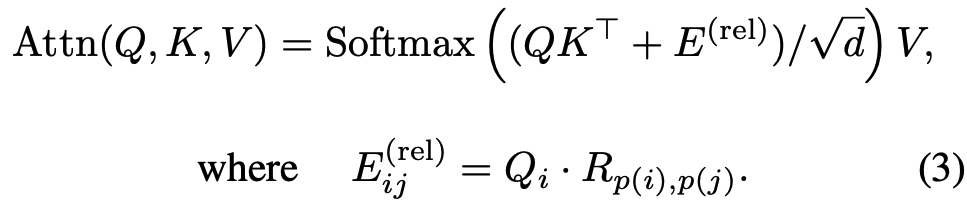
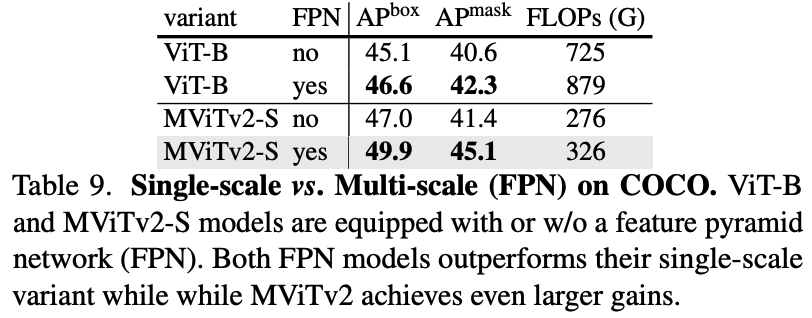
- FPN Integration: The hierarchical, multi-scale feature maps produced by MViTv2 naturally integrate with the top-down structure of a Feature Pyramid Network (FPN), a standard for modern object detectors (Figure 3).
- Initialization for Video: To adapt a 2D ImageNet pre-trained model for video, convolutional layers are “inflated” to handle the time dimension, and the new temporal relative position embeddings are simply initialized to zero.
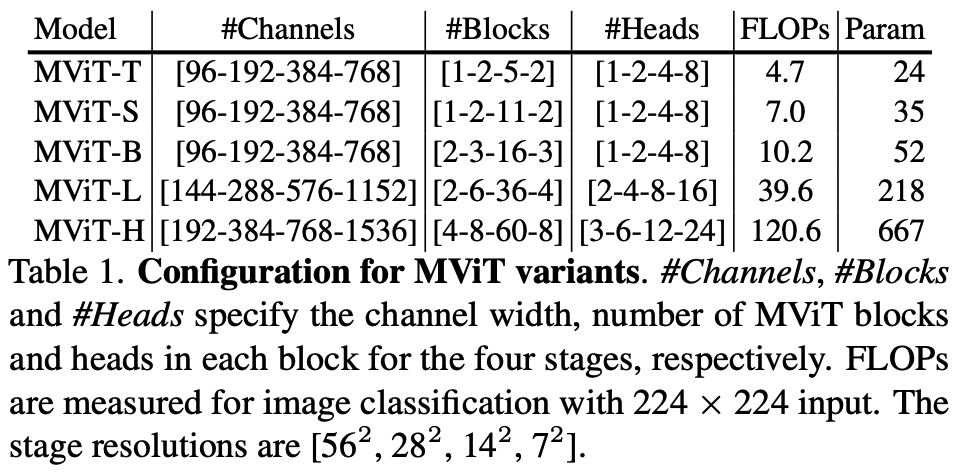
Architecture Variants: Five models of increasing capacity are defined: Tiny (T), Small (S), Base (B), Large (L), and Huge (H), by scaling the channel dimensions, number of blocks per stage, and number of attention heads (Table 1).
loss functions
The work utilizes standard, well-established loss functions for each task without proposing novel formulations:
- Classification: Cross-entropy with label smoothing (0.1).
- Detection/Segmentation: The standard losses defined by the Mask R-CNN and Cascade Mask R-CNN frameworks
experimental results
Datasets: Experiments are conducted on a comprehensive set of large-scale public benchmarks to validate the model’s generalizability.
- Image Classification: ImageNet-1K and ImageNet-21K.
- Object Detection & Instance Segmentation: MS-COCO.
- Video Action Classification: Kinetics-400, Kinetics-600, Kinetics-700, and Something-Something-v2 (SSv2).
- Video Action Detection: AVA v2.2
Experimental Setup:
- Baselines: MViTv2 is rigorously compared against other leading Transformer architectures (Swin, DeiT, ViL, ViT) and strong CNNs (ResNet, ResNeXt, EfficientNet).
- Ablation Studies: A series of controlled experiments are performed to isolate the impact of each proposed component:
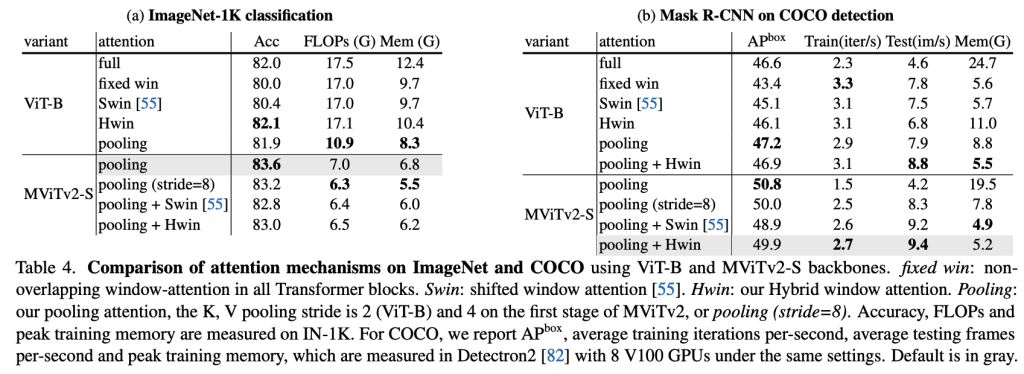
- The choice of attention mechanism (pooling vs. windowed vs. hybrid).
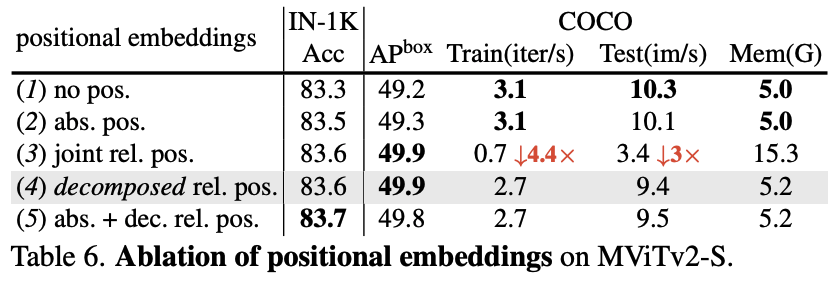
- The effect of different positional embedding schemes.
- The contribution of the residual pooling connection.
- The benefit of a native multi-scale design with FPN.
- Metrics: Standard metrics are used for each task: Top-1 Accuracy for classification , APbox and APmask for detection , and mAP for action localization
Results:
- ImageNet Classification:
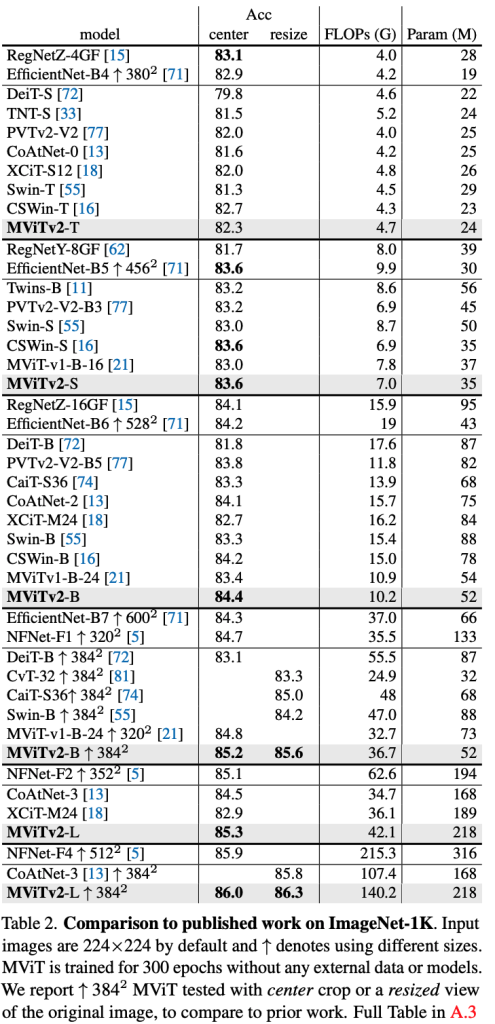
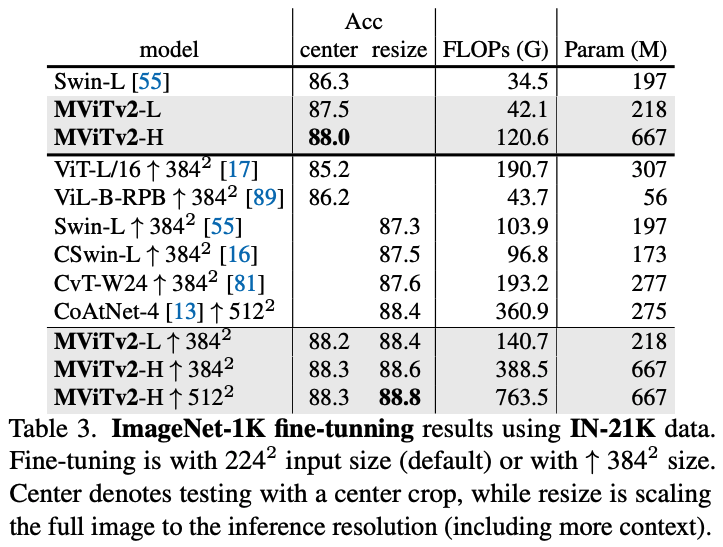
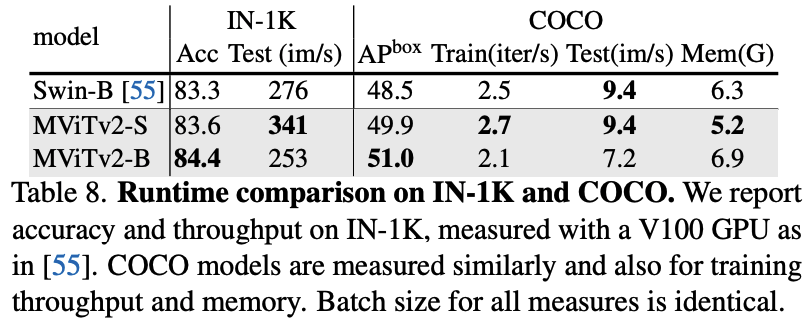
- MViTv2 consistently outperforms MViTv1 and other transformers like Swin and DeiT, often with better efficiency. For instance, MViTv2-B achieves 84.4% Top-1 accuracy, surpassing Swin-B by 1.1% with 33% fewer FLOPs.
- With ImageNet-21K pre-training, MViTv2-L and MViTv2-H achieve SOTA results of 88.4% and 88.8%, respectively.
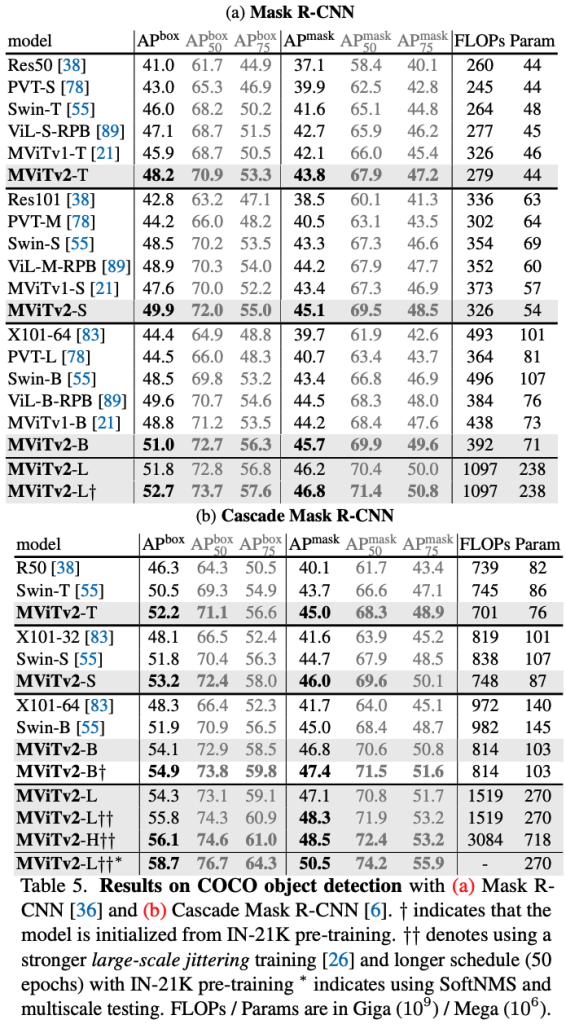
- COCO Object Detection:
- Using Mask R-CNN, MViTv2-B outperforms Swin-B by a significant margin of +2.5 APbox.
- With a stronger Cascade Mask R-CNN framework, multi-scale testing, and SoftNMS, MViTv2-L achieves a state-of-the-art 58.7 APbox, surpassing previous best results.
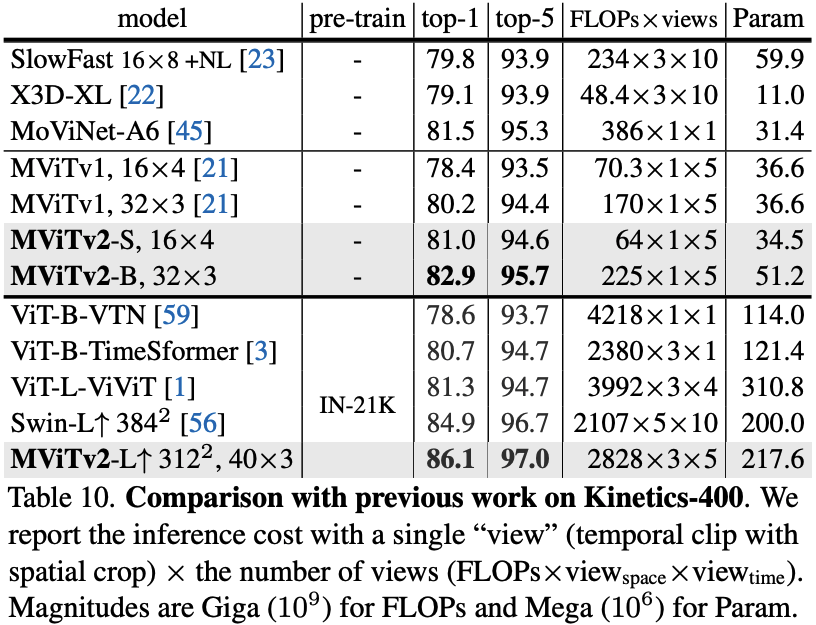
- Video Recognition:
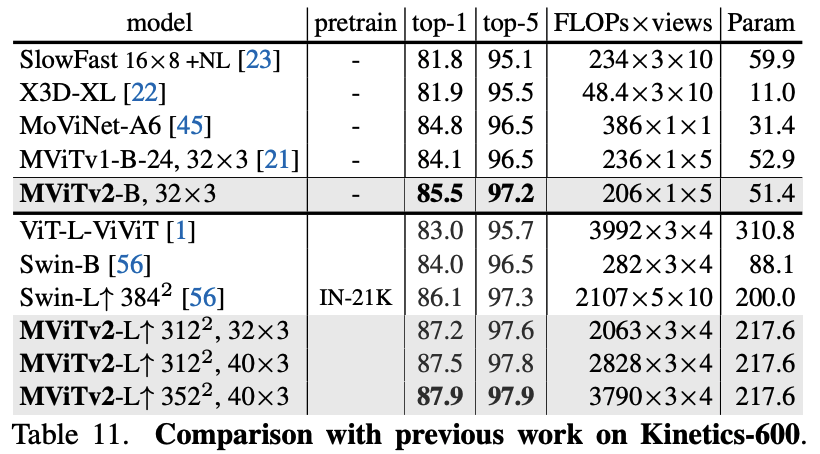
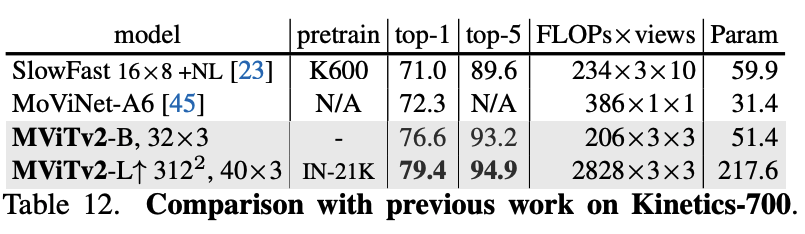
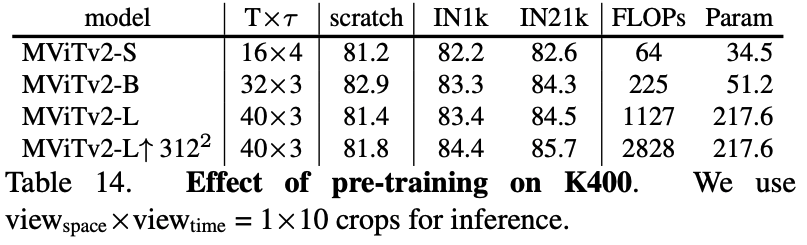
- Kinetics: On K-400, MViTv2-B trained from scratch achieves 82.9%, a +2.7% improvement over its MViTv1 counterpart. On K-600, it surpasses even IN-21K pre-trained models. The large model, MViTv2-L, sets new SOTA performance on K-400 (86.1%), K-600 (87.9%), and K-700 (79.4%).
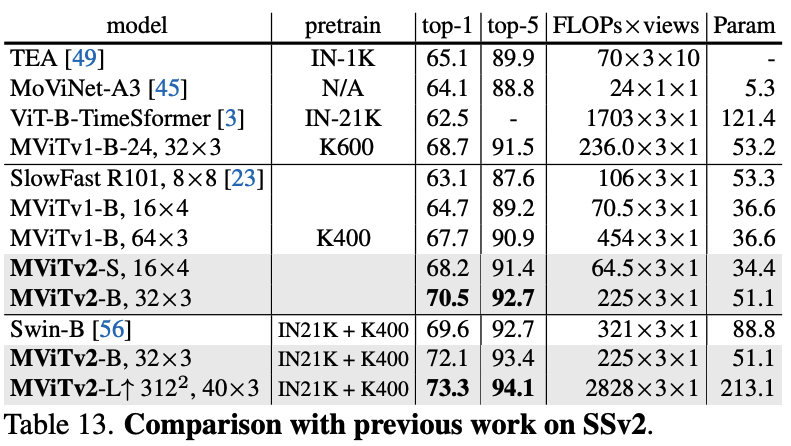
- Something-Something-v2: On this temporally-focused dataset, MViTv2 shows large gains, with MViTv2-B surpassing the previous best by +0.9% even without extra pre-training data.
- Key Ablation Findings:
- Pooling Attention is Superior: Simple pooling attention is a strong and efficient baseline, outperforming windowed attention for both classification and detection in terms of accuracy/compute trade-off.
- Core Improvements are Crucial: The decomposed relative positional embeddings and the residual pooling connection are both shown to be necessary, providing significant performance gains across all tasks.
- Multi-Scale Design Matters: The native hierarchical design of MViTv2 benefits much more from an FPN (+2.9 APbox) than a single-scale ViT backbone (+1.5 APbox), confirming the design’s effectiveness for dense prediction.
conclusion and future work
Conclusion
- This paper presents MViTv2, an improved Multiscale Vision Transformer that serves as a powerful and general hierarchical architecture for a wide range of visual recognition tasks.
- The simple-yet-effective architectural improvements—decomposed relative positional embeddings and residual pooling connections—are the key drivers behind its performance.
Future Work
- Limitations: The hyper-parameters for MViTv2 were largely adopted from previous works to ensure fair comparisons, meaning the reported results might be sub-optimal and could potentially be improved with more extensive, task-specific tuning.
- Future Directions: The paper suggests two promising avenues for future research:
- Scaling Down: Designing even smaller, more efficient MViTv2 variants suitable for mobile and edge device applications.
- Scaling Up: Developing even larger MViTv2 models to better leverage massive, web-scale datasets.
Reference
- Li, Y., Wu, C. Y., Fan, H., Mangalam, K., Xiong, B., Malik, J., & Feichtenhofer, C. (2021). MViTv2: Improved Multiscale Vision Transformers for Classification and Detection. in arXiv preprint arXiv:2112.01526.
- Self-Attention with Relative Position Representations

Leave a Reply