


OpenAI has released gpt-oss-120b and gpt-oss-20b, two state-of-the-art, open-weight language models available under the Apache 2.0 license. These text-only models are designed for strong real-world performance, tool use, and reasoning, all while being efficient enough to run on consumer-grade hardware.
The models are customizable, provide full chain-of-thought (CoT), and support Structured Outputs.
Models
- gpt-oss-120b (achieves near-parity with OpenAI o4-mini on core reasoning benchmarks): for production, general-purpose, high-reasoning use cases that fit into a single H100 GPU (117B parameters with 5.1B active parameters).
- gpt-oss-20b (delivers similar results to OpenAI o3‑mini on common benchmarks): for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters).
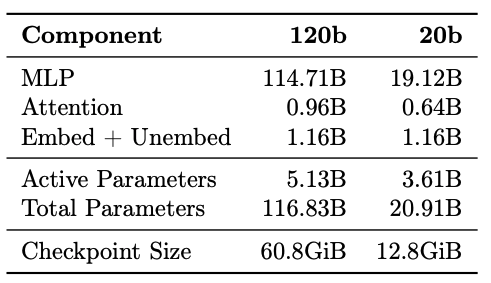
model architecture
Autoregressive Mixture-of-Experts (MoE) Transformer:
- gpt-oss-120b: 116.8B total parameters (5.1B active), 36 layers, 128 experts per MoE block.
- gpt-oss-20b: 20.9B total parameters (3.6B active), 24 layers, 32 experts per MoE block.
Quantization: MoE weights are quantized to MXFP4 format (4.25 bits), reducing memory footprint significantly and allowing the 120b model to run on a single 80GB GPU.
Attention: Uses Grouped Query Attention (GQA) with 64 query heads and 8 key-value heads. The context length is extended to 131,072 tokens using YaRN.
Tokenizer: A 201,088-token BPE tokenizer (0200k_harmony) built for the custom chat format.
Pre-training
Models were trained on trillions of text tokens with a focus on STEM, coding, and general knowledge. The knowledge cutoff is June 2024.
Safety-filtered data was used, specifically reusing CBRN (Chemical, Biological, Radiological, Nuclear) filters from GPT-4o to mitigate risks.
Training was conducted on NVIDIA H100 GPUs using PyTorch, with gpt-oss-120b requiring 2.1 million H100-hours.
Leverage the Flash Attention algorithms to reduce the memory requirements and accelerate training.
Post training
Chain-of-Thought Reinforcement Learning (CoT RL) techniques, similar to those used for OpenAI 03, were employed to teach reasoning, problem-solving, and tool use.
Deliberative Alignment was used to teach the model to refuse harmful requests and adhere to the instruction hierarchy.
Tool uses
The gpt-oss models are excellent for:
- Web browsing (using built-in browsing tools).
- Function calling with defined schemas.
- Agentic operations like browser tasks.
Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This larger model gpt-oss-120b can be fine-tuned on a single H100 node, whereas the smaller gpt-oss-20b can even be fine-tuned on consumer hardware.
Reference
- https://openai.com/index/introducing-gpt-oss/
- https://huggingface.co/openai/gpt-oss-120b
- https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
- RoFormer: Enhanced Transformer with Rotary Position Embedding

Leave a Reply