-
YOLOs Family – A Research Review
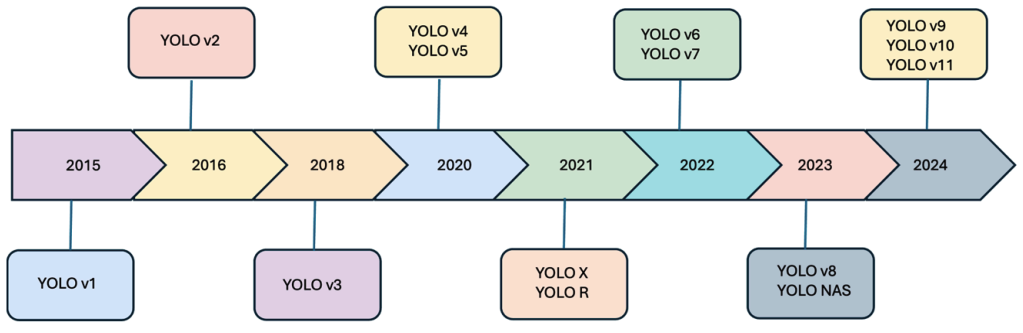
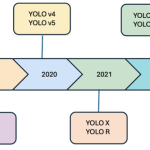
This aims to provide a comprehensive review of the YOLO (You Only Look Once) framework, tracing its evolution up to the latest version, YOLOv11. The goal is to analyze architectural improvements, evaluate performance on benchmarks, survey its applications, and identify research gaps for future work. Introduction Motivation There is a growing demand for object detection
-
YOLOv5
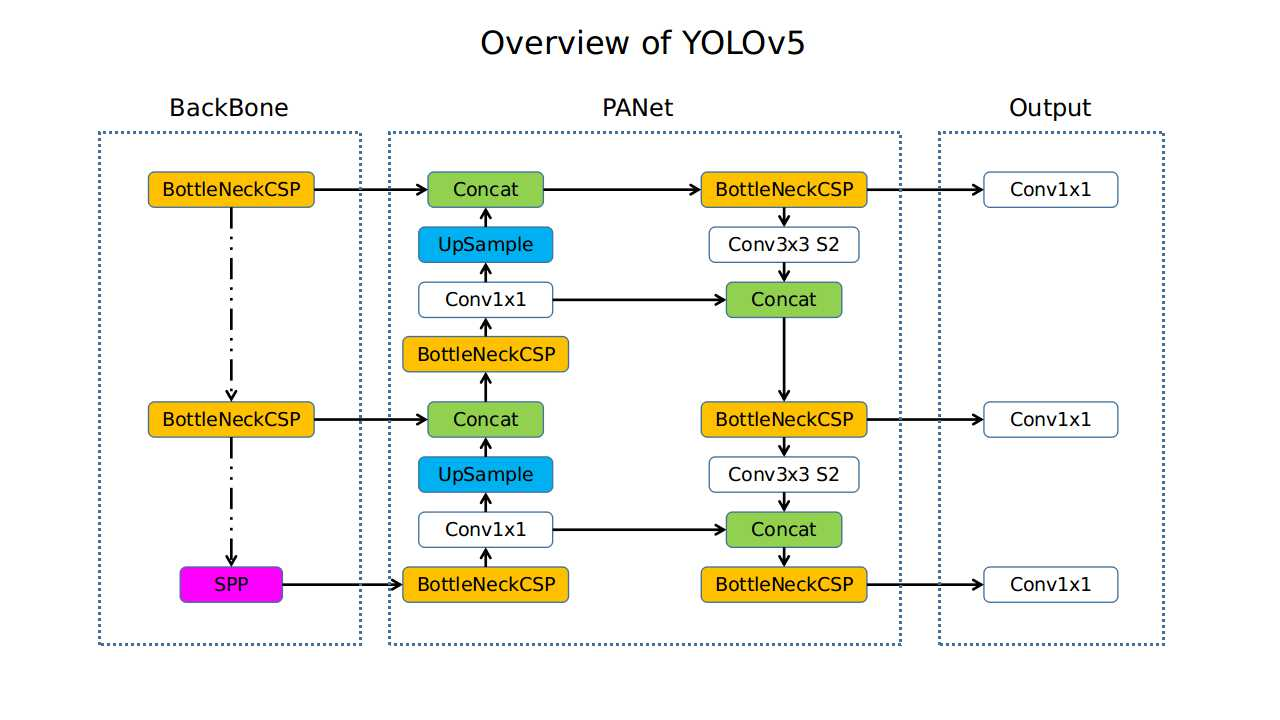
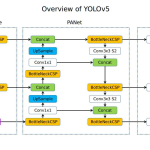
Introduction Objective YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. Framework Contribution A defining contribution of YOLOv5 was its native implementation within the PyTorch framework. Ultralytics provides a family of pre-configured models—YOLOv5n (nano), YOLOv5s (small), YOLOv5m (medium), YOLOv5l (large), and YOLOv5x (extra-large)—that all share the same underlying architecture but vary in size
-
Object Detection – A Research Review
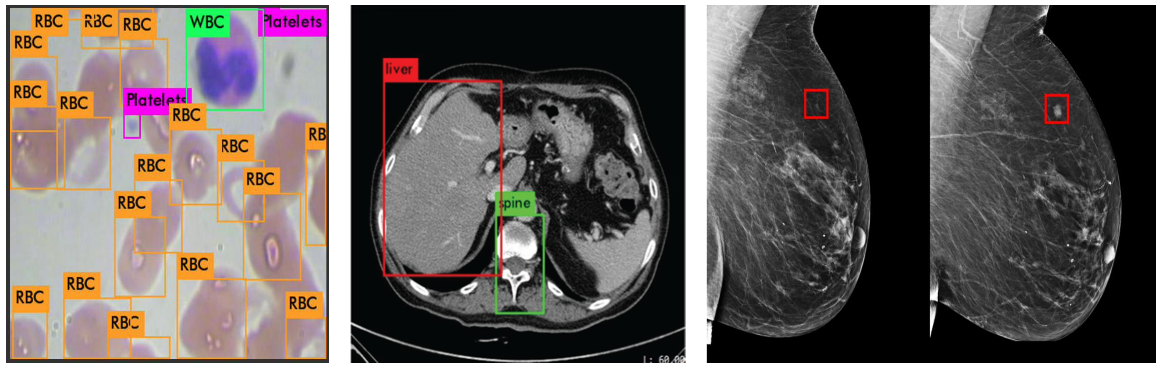
Introduction Object detection is a computer vision task that involves identifying and localizing objects within an image or video. It consists of two main steps: The output of an object detection model for each identified instance is a tuple comprising a class label (ci), the bounding box parameters (e.g., center coordinates, width, and height: xi,
-
MViTv2: Improved Multi-scale Vision Transformersfor Classification and Detection
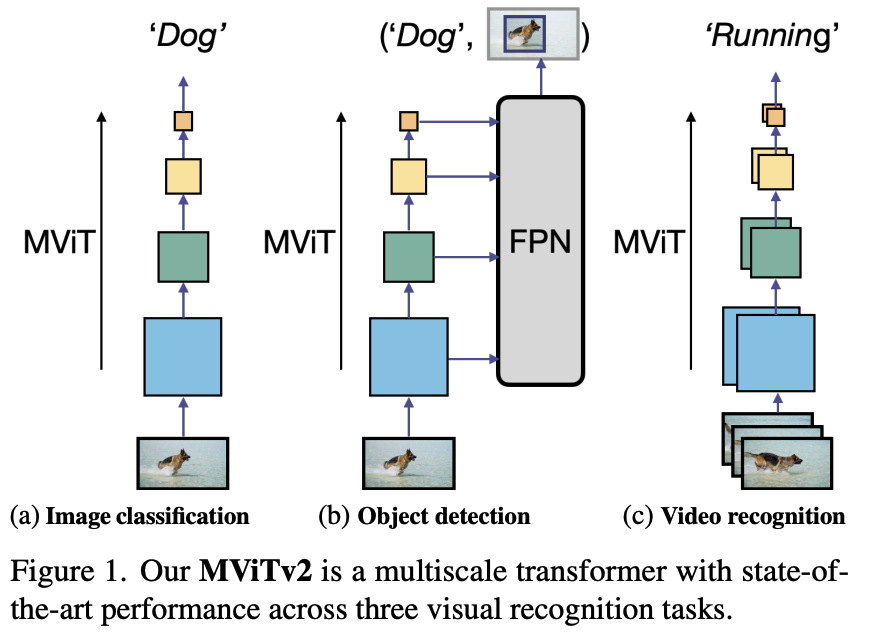
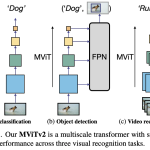
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection Facebook AI Research, UC Berkeley Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. Introduction Motivation Designing a single, simple, yet effective architecture for diverse visual recognition tasks (image, video, detection). While Vision Transformers (ViT) are powerful, their standard architecture struggles with
-
MViT: Multiscale Vision Transformer
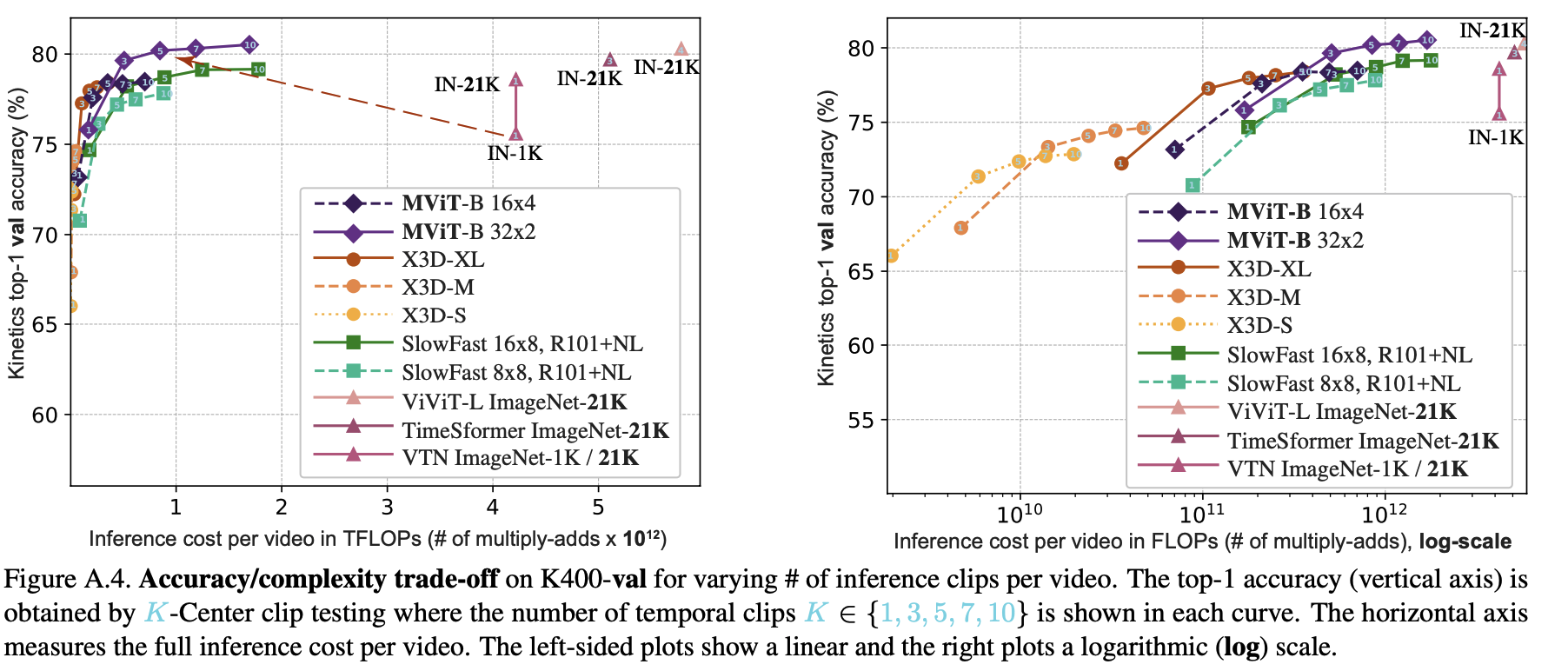
Multiscale Vision Transformers Facebook AI Research, UC Berkeley Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. Introduction Motivation Convolutional Neural Networks (CNNs) have long benefited from multiscale feature hierarchies (pyramids), where spatial resolution decreases while channel complexity increases through the network. Vision Transformers (ViT) maintain a constant resolution and channel capacity throughout,
-
Segment Anything (SAM)
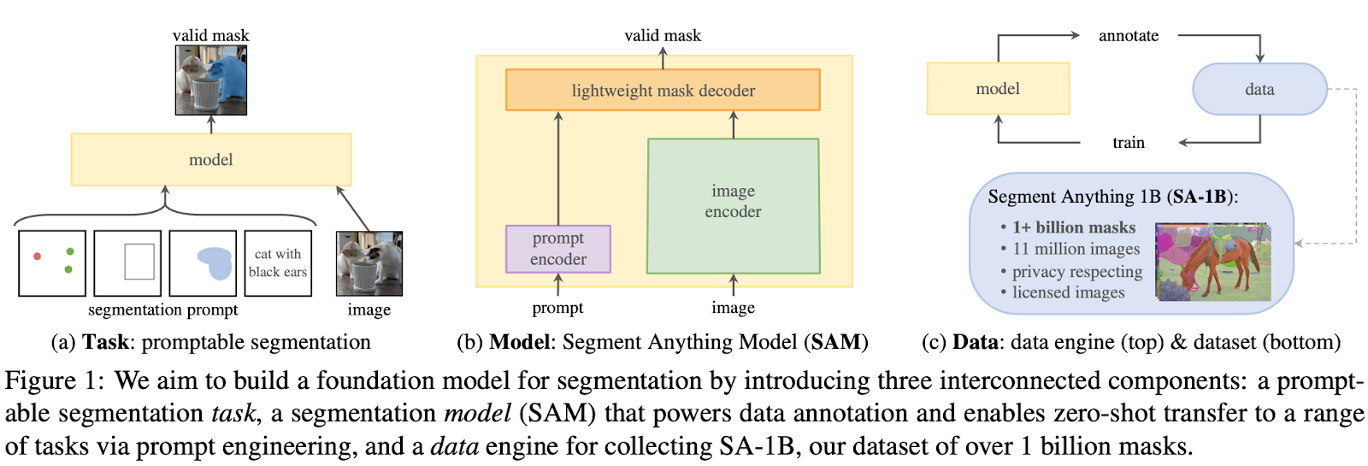
SAM: Segment Anything Meta AI Research, FAIR Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4015-4026, 2023. Introduction Motivation Objective Segment Anything (SAM) = Interactive Segmentation + Automatic Segmentation Segment Anything: Simultaneously develop a general, promptable segmentation model and use it to create a segmentation dataset of unprecedented scale. Related Works Foundation
-
[ViT] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
![[ViT] An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale](https://lephongphu.site/wp-content/uploads/2025/05/image-31.png)
ViT: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale Google Research, Brain Team The 9th International Conference on Learning Representations, ICLR, 2021. Introduction Motivation The Transformer model and its variants have been successfully shown that they can be comparable to or even better than the state-of-the-art in several tasks, especially in the field of NLP. Objective Related
Categories
- AI News (1)
- AI Roadmap (7)
- Better Version (15)
- Business (3)
- Courses (2)