

Multiscale Vision Transformers
Facebook AI Research, UC Berkeley
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
Introduction
Motivation
Convolutional Neural Networks (CNNs) have long benefited from multiscale feature hierarchies (pyramids), where spatial resolution decreases while channel complexity increases through the network.
Vision Transformers (ViT) maintain a constant resolution and channel capacity throughout, which may not be optimal for dense visual signals like images and videos.
Standard ViTs also struggle to effectively model temporal information in videos, often relying more on appearance cues.
Objective
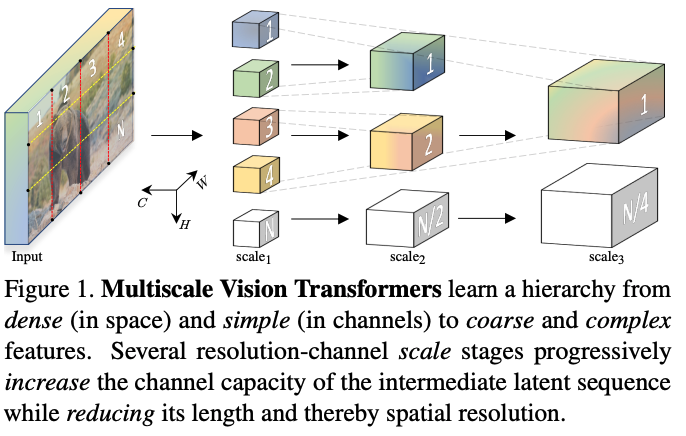
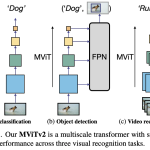
MViT, a Multiscale Vision Transformer model for video and image recognition, is designed by connecting the seminal idea of (1) multiscale feature hierarchies with (2) transformer models.
Related Works
- Convolutional Networks (ConvNets): The de-facto standard for vision tasks, ConvNets inherently incorporate multiscale processing through pooling layers. MViT adopts this hierarchical design principle.
- Vision Transformers (ViT): Recent works like ViT and DeiT have shown the power of transformers in vision, but typically use a single-scale architecture with uniform resolution. Concurrent video transformers often apply the vanilla ViT model with minimal changes and depend heavily on large-scale pre-training (e.g., ImageNet-21K).
- Efficient Transformers: Other research has focused on reducing the quadratic complexity of attention for NLP tasks, which is complementary to MViT’s architectural approach to efficiency.
Global Framework
Multiscale Vision Transformer (MViT), an architecture with multiple stages, has features of:
- Hierarchical model: It begins with a high spatiotemporal resolution and a low channel dimension. Through the network’s stages, the spatial resolution is progressively down-sampled while the channel capacity is expanded.
- Pyramid strategies: This creates a feature pyramid within the transformer, allowing early layers to model simple, local information and deeper layers to capture complex, global semantics.
Contributions
A Multiscale Hierarchical Architecture for Vision Transformers: MViT progressively expands channel capacity while reducing spatiotemporal resolution.
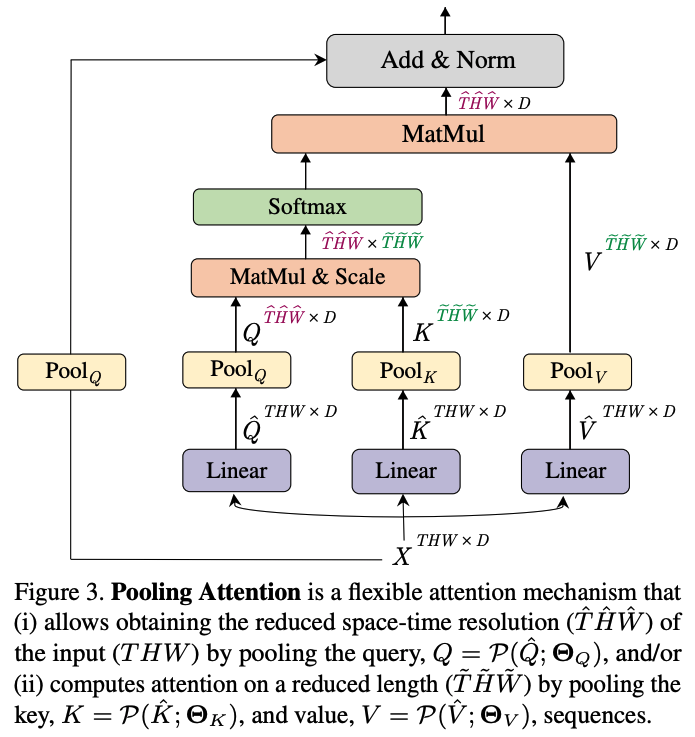
Multi-Head Pooling Attention (MHPA): A flexible attention mechanism is proposed that enables resolution reduction within the transformer blocks by pooling the Query (Q), Key (K), and Value (V) tensors.
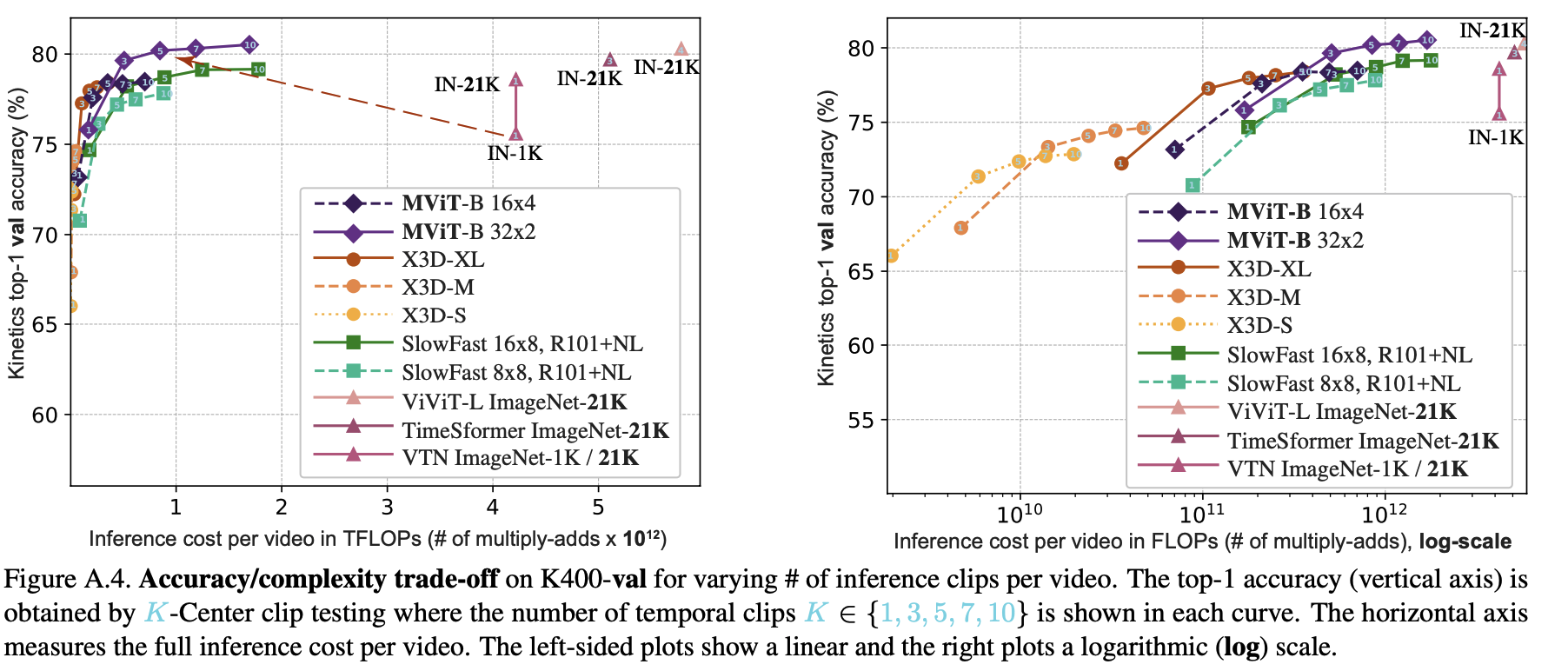
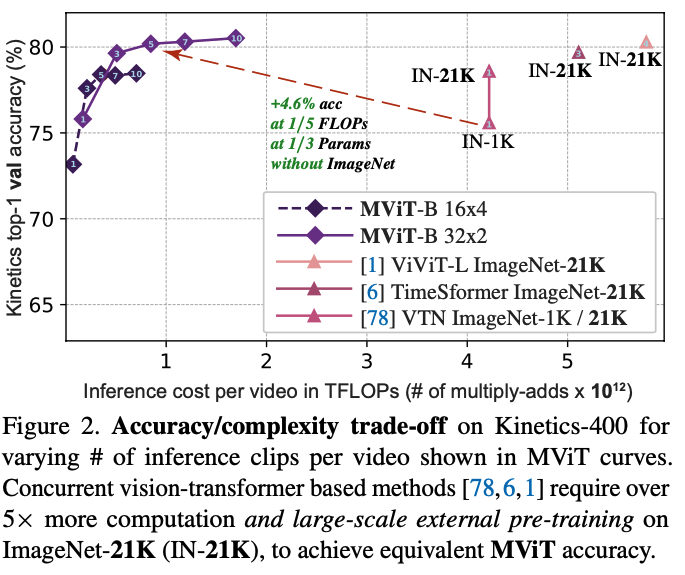
State-of-the-Art Performance: MViT achieves superior results on major video recognition benchmarks (Kinetics, SSv2, etc.) and image classification (ImageNet) compared to concurrent transformer models, while being significantly more efficient in terms of computation (FLOPs) and parameters, notably without requiring large-scale external pre-training data.
Details
Multi-head Pooling Framework (MHPA)
Multi-Head Pooling Attention (MHPA): a self-attention operator that enables flexible resolution modeling in a transformer block, allowing Multiscale Transformers to operate at progressively changing spatiotemporal resolution.
MHPA pools the sequence of latent tensors to reduce the sequence length (resolution) of the attended input.
Pooling Operator
The fundamental mechanism that enables resolution reduction within the MViT architecture.
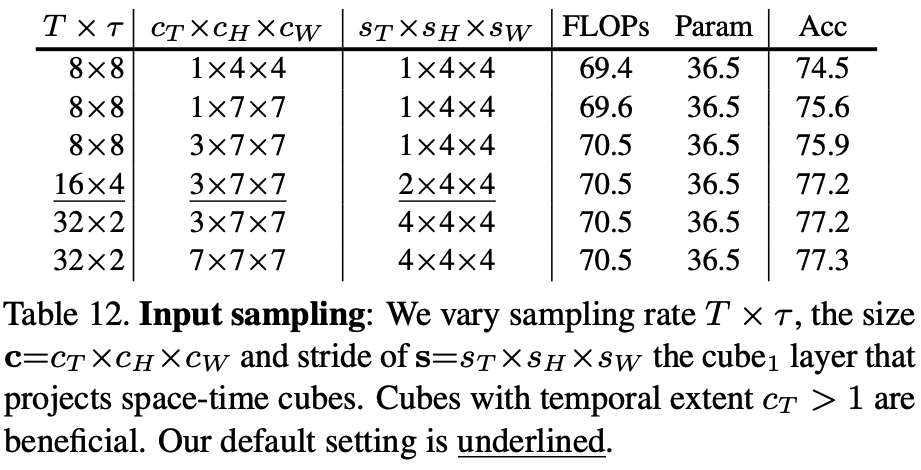
Function: Performs a standard pooling computation (like max-pooling or average-pooling) on an input tensor. It operates along each dimension (temporal, height, and width) of the input sequence.
Parameters: The operator is defined by its parameters Θ=(k,s,p), which represent:
- k: The kernel size (e.g.,
kT×kH×kW). - s: The stride dimensions (e.g.,
sT×sH×sW). - p: The padding dimensions (e.g.,
pT×pH×pW).
Outcome: The primary goal of this operator is to reduce the sequence length L of an input tensor to a shorter length L~. By applying a stride s, the sequence length is reduced by a factor of sT⋅sH⋅sW.
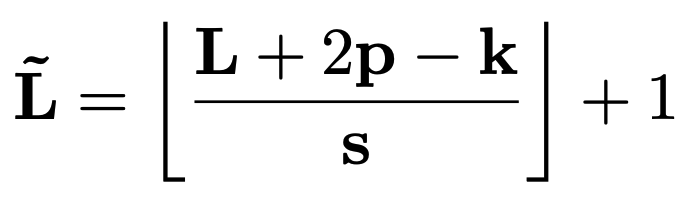
Pooling Attention
Pooling Attention is a modified self-attention mechanism that incorporates the Pooling Operator to flexibly model different resolutions and reduce computational complexity.
The key distinction from standard attention is that this computation is performed on the pooled, reduced-length sequences, which has two major benefits:
- Resolution Reduction: By pooling the query (Q) tensor with a stride greater than one, the spatial-temporal resolution of the output is reduced.
- Computational Efficiency: By pooling the key (K) and value (V) tensors, the quadratic complexity of the attention mechanism with respect to sequence length is dramatically decreased, saving both computation and memory.
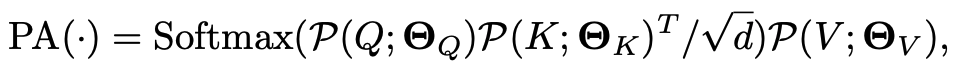
MViT Architecture
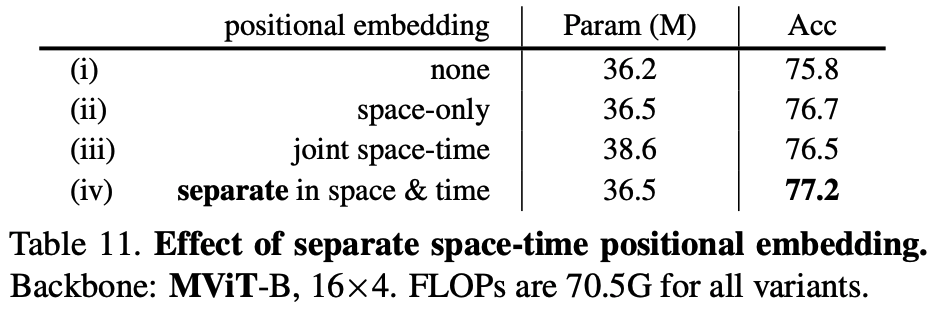
The key concept of Multiscale Vision Transformers (MViT) is to progressively increase the channel dimension while simultaneously decreasing the spatiotemporal resolution throughout the network.
This design results in an architecture where early layers have fine-grained spacetime resolution and a low channel count, which transitions to coarse spacetime resolution and a high channel count in the later layers.
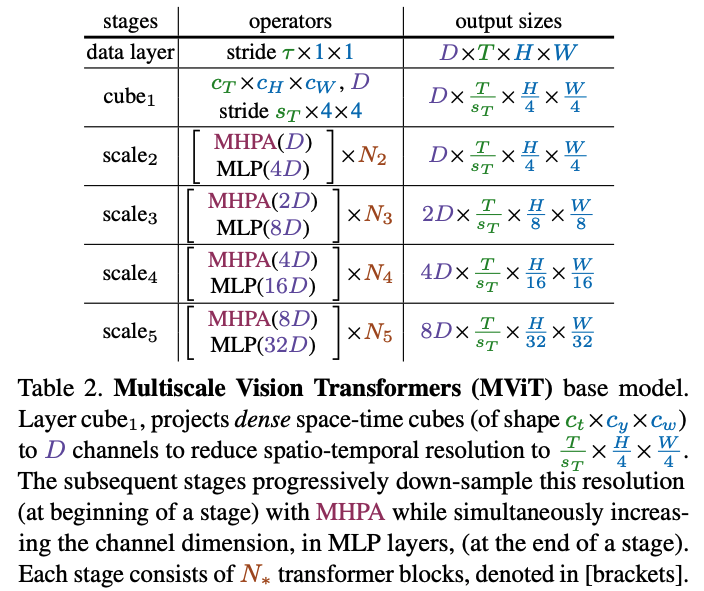
Architectural Components
Scale Stages
- Scale stage is a set of
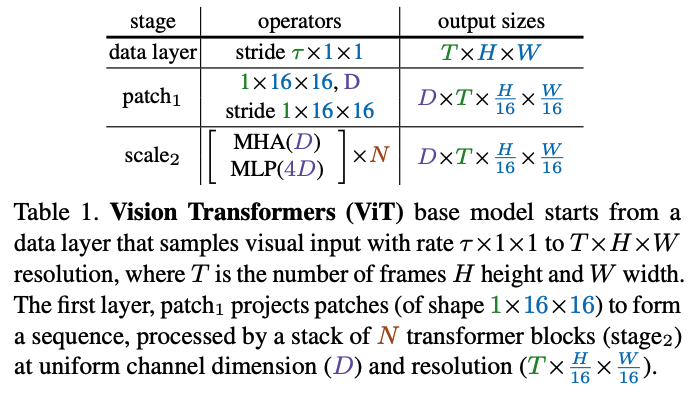
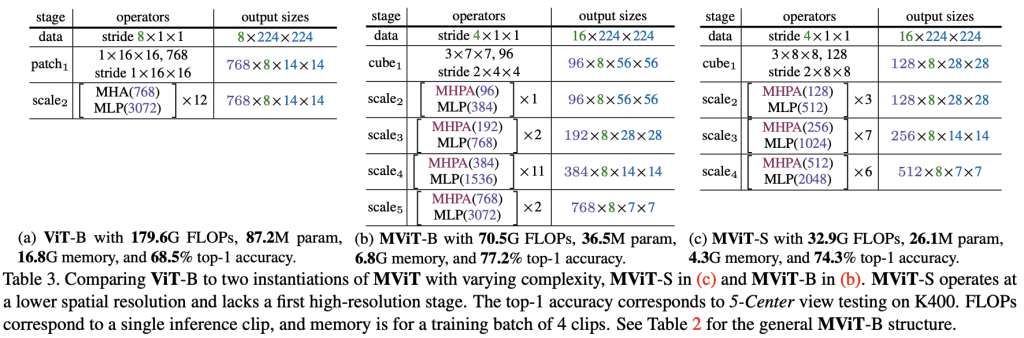
Ntransformer blocks that operate on an identical scale (i.e., same channel, temporal, height, and width dimensions)D×T×H×W. - ViT (Table 1) always uses the same scale at scale2.
- MViT (Table 2) uses multiple stages to downsize tensors for attention.
- At the network’s input (
cubestage), visual patches are projected into a long sequence with a small channel dimension (e.g., 8x smaller than a typical ViT model), but long sequence (e.g. 4×4 = 16× denser than a typical ViT model)
Stage Transitions: When moving from one stage to the next, two things happen simultaneously:
- The sequence length is down-sampled, reducing spatiotemporal resolution.
- The channel dimension is up-sampled, allowing the network to learn more complex features.
Channel Expansion: The channel dimension is expanded in proportion to the reduction in resolution. For example, if the spatiotemporal resolution is down-sampled by a factor of 4, the channel dimension is increased by a factor of 2.
Pooling Mechanisms
MViT uses different pooling strategies for different purposes:
- Query Pooling: Pooling is applied to the query (Q) tensor only in the first layer of each stage. This is what reduces the sequence’s output resolution. In all other layers within a stage, the query stride is set to 1 to maintain the resolution.
- Key-Value Pooling: Pooling the key (K) and value (V) tensors does not change the output resolution but is crucial for reducing the overall computational requirements of the attention operation. This type of pooling is used in all layers except the first layer of each stage where query pooling occurs.
Handling Dimension Mismatches
Channel Mismatch: To handle the increase in channel dimensions between stages, an extra linear layer is applied to the skip connection.
Skip Connections: Because dimensions change between stages, skip connections must be modified.
Resolution Mismatch: To match the reduced resolution caused by query pooling, the skip connection is also pooled.
Network instantiation details
MViT-Base model is composed of 4 scale stages. It processes input differently from a standard Vision Transformer.
MViT-B and MViT-S are more efficient than ViT-B.
Loss Functions
The classification tasks evaluated imply a Cross-Entropy Loss.
The use of Label Smoothing modifies the standard cross-entropy target.
Experimental Results
Data Collection
Video Datasets
- Kinetics-400 (K400) & Kinetics-600 (K600): Large-scale action classification datasets. Used for primary evaluation and as a pre-training source.
- Something-Something-v2 (SSv2): A dataset focused on human-object interactions, requiring strong temporal reasoning.
- Charades: Features longer-range activities in a multi-label classification setting.
- AVA v2.2: A dataset for spatiotemporal localization of human actions (detection).
Image Dataset
- ImageNet-1K: The standard large-scale dataset for image classification. MViT video models are adapted by simply removing the temporal dimension.
Experimental Setup
- Video: Models are trained from scratch for 200 epochs on Kinetics. For transfer learning tasks (SSv2, Charades, AVA), models are fine-tuned from their Kinetics-trained checkpoints.
- Image: Models are trained from scratch on ImageNet for 300 epochs, following the DeiT recipe for fair comparison.
Training Setup
- From Scratch: All MViT models are trained from random initialization (“from scratch”) on the target datasets (e.g., Kinetics), a key differentiator from other ViT models that require ImageNet pre-training.
- Optimizer: Synchronized AdamW optimizer is used.
- Learning Rate: A base learning rate of 1.6⋅10−3 (for a batch size of 512) with a linear warm-up for the first 30 epochs, followed by a half-period cosine decay schedule.
- Regularization: A strong regularization scheme is employed, including:
- Weight decay of 5⋅10−2.
- Label smoothing (0.1).
- Stochastic Depth (drop-connect) with a rate of 0.2.
- Advanced data augmentation: Mixup, CutMix, Random Erasing, and RandAugment.
Inference Setup
- For video recognition, predictions are aggregated from multiple views.
- Temporal Sampling: K clips (e.g., K=5) are uniformly sampled from a full-length video.
- Spatial Sampling: For each clip, either a single center crop (e.g., 224×224) or 3 spatial crops are taken.
- The final prediction is the average of scores from all individual views.
Results
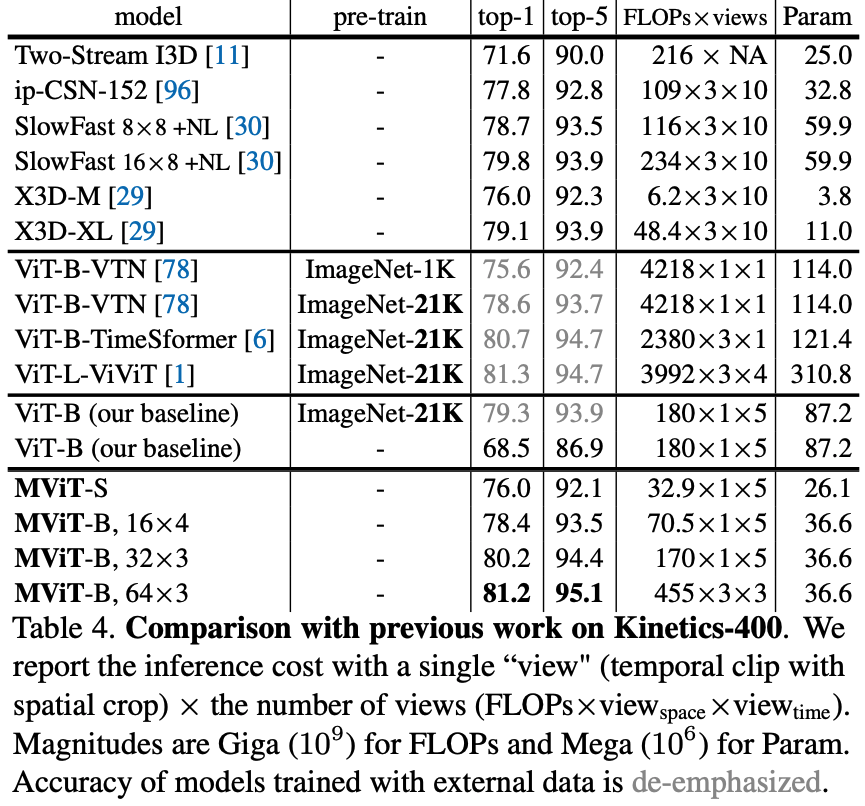
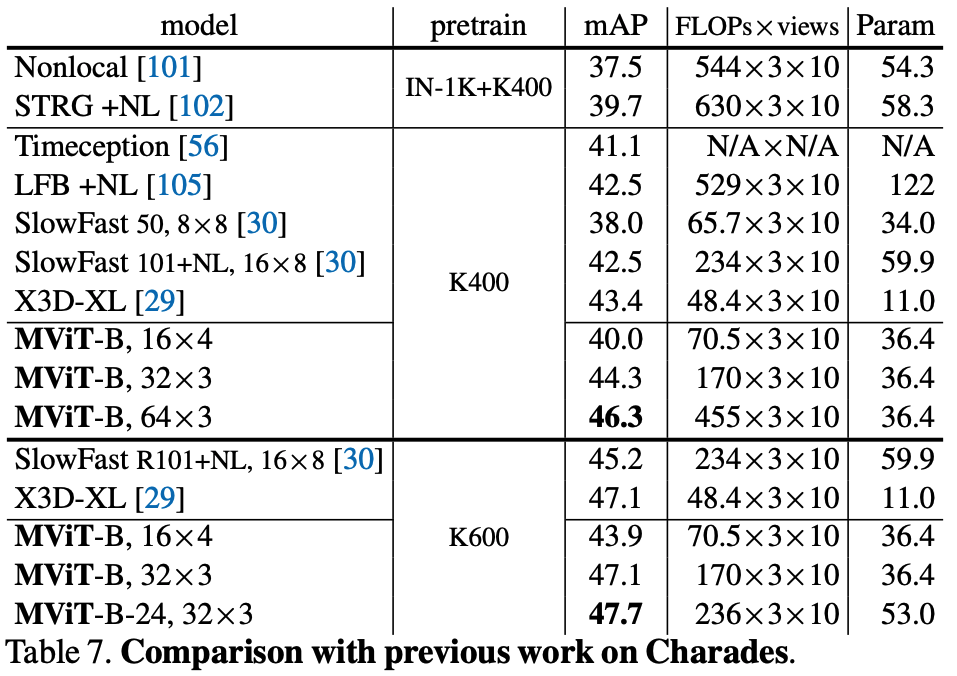
Key Findings on Kinetics-400 (Table 4)
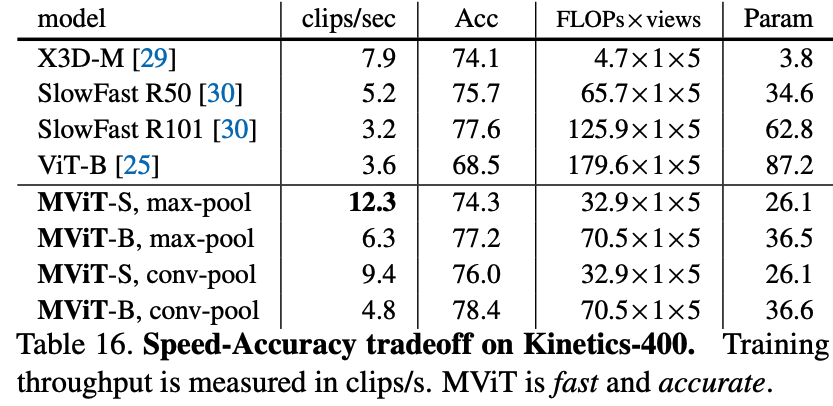
- MViT vs. ViT (from scratch): Base model, MViT-B (16×4 sampling), achieves 78.4% top-1 accuracy. This is a +9.9% improvement over our baseline ViT-B (68.5%) trained under identical from-scratch conditions, while using 2.6x fewer FLOPs and 2.4x fewer parameters.
- MViT vs. Pre-trained SOTA: With more temporal frames (64×3), MViT-B reaches 81.2% top-1 accuracy. This result is competitive with concurrent methods like ViViT-L (81.3%) and TimeSformer (80.7%), but those methods are 5-10x more costly and rely on large-scale ImageNet-21K pre-training.
- Frame Shuffling (Table 9): When inference frames are shuffled, ViT-B performance is unaffected (68.5% -> 68.4%), indicating it ignores temporal order. MViT-B performance drops significantly (77.2% -> 70.1%), demonstrating it effectively learns temporal information.
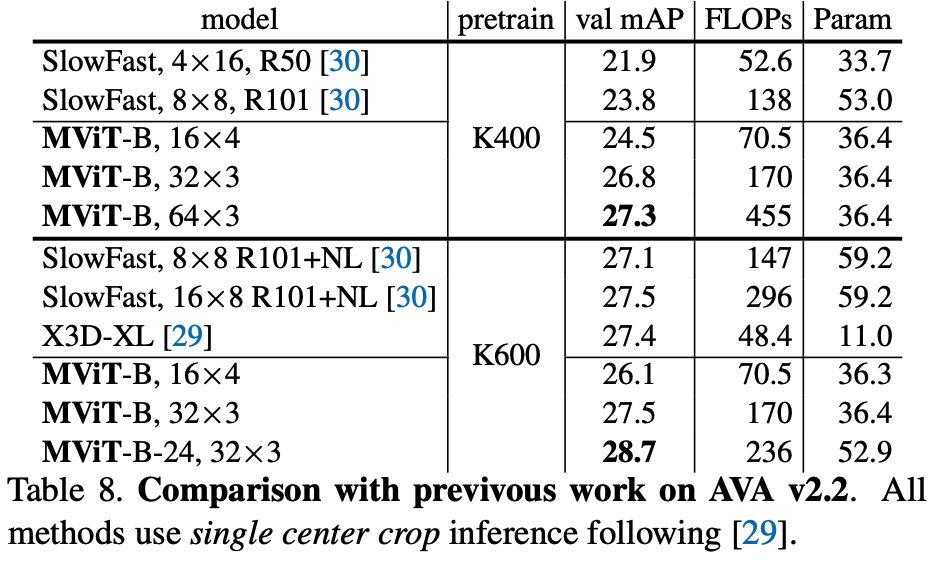
Performance on Other Datasets
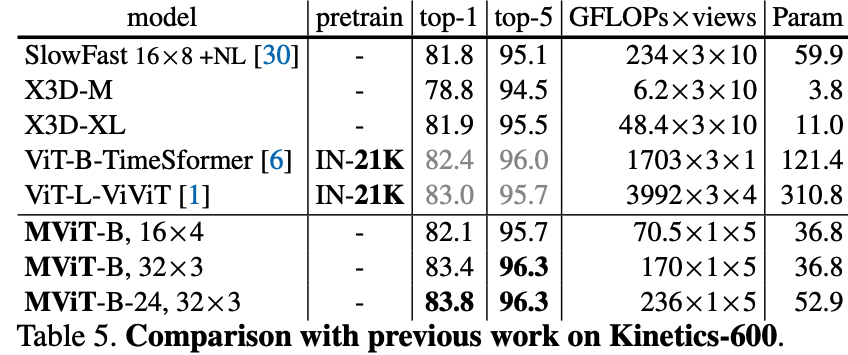
- Kinetics-600 (Table 5): MViT-B achieves a state-of-the-art result of 83.4% when trained from scratch.
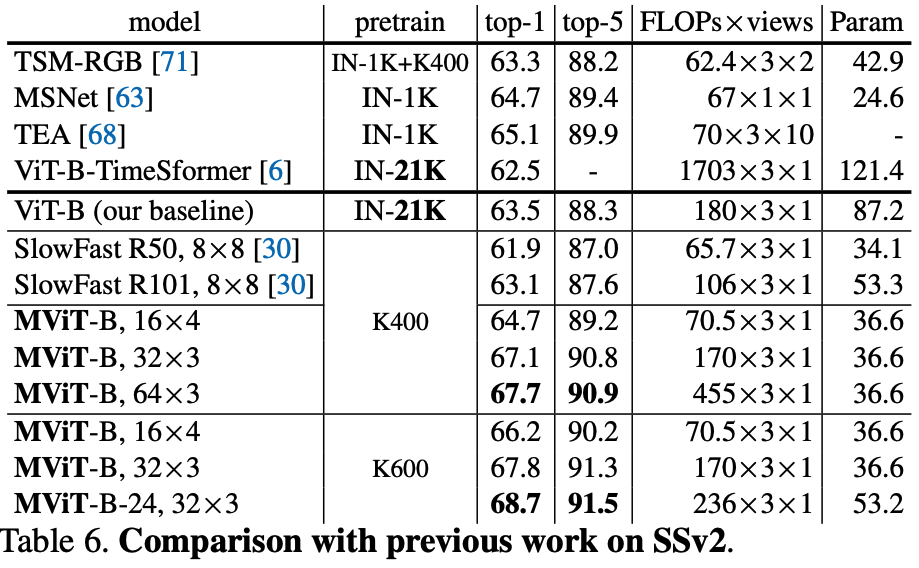
- SSv2 (Table 6): MViT demonstrates strong temporal modeling, outperforming SlowFast and achieving 68.7% top-1 with a deeper model.
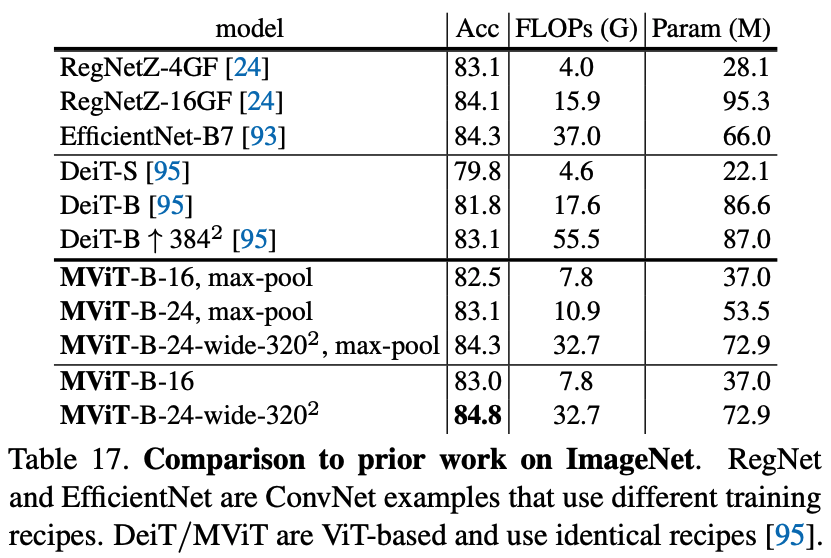
- ImageNet (Table 17): The image-based MViT-B outperforms its direct counterpart, DeiT-B, by +0.7% (82.5% vs. 81.8%) with 2.3x fewer FLOPs. With convolutional pooling, this rises to 83.0%.


Conclusion and Future Work
Conclusion
- This work successfully connects the fundamental computer vision principle of multiscale feature hierarchies with the powerful Transformer architecture.
- Multiscale Vision Transformer (MViT) hierarchically expands feature complexity while reducing visual resolution, creating a feature pyramid within the model.
- Multi Head Pooling Attention (MHPA) operator is a key enabler of this design, providing architectural flexibility and computational efficiency.
Future Work
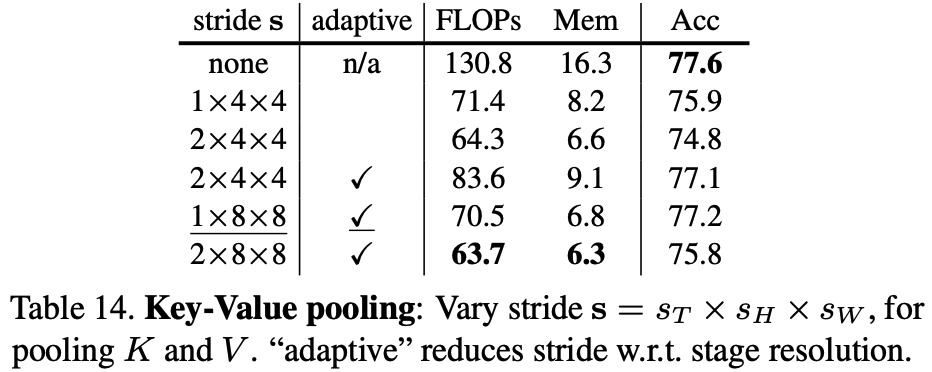
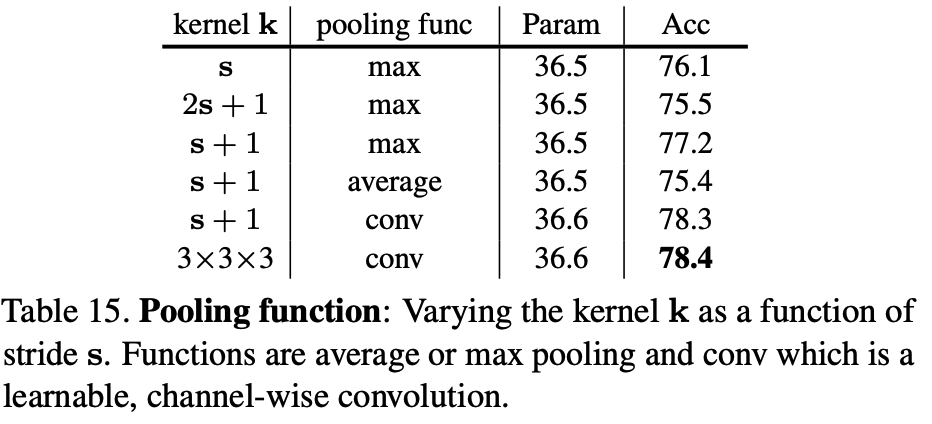
- Investigating more advanced pooling mechanisms beyond the max, average, and depthwise separable convolutions explored in the ablations.
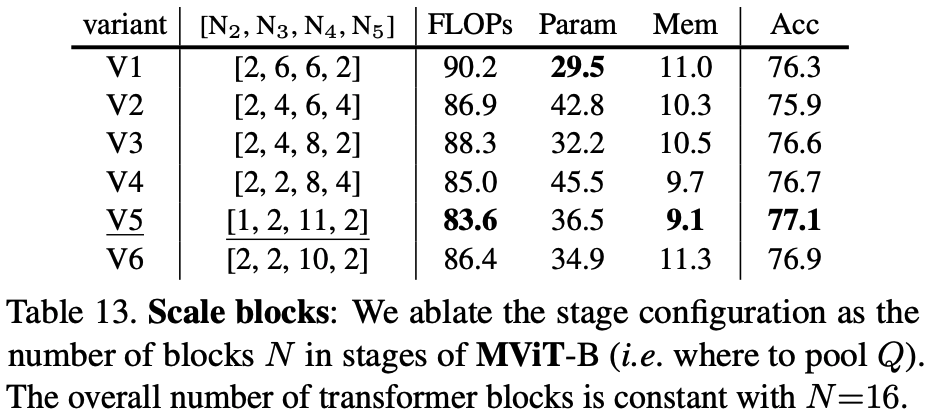
- Exploring different strategies for stage configuration and channel expansion.
- Applying MViT to other dense prediction tasks like semantic segmentation and object detection, where multiscale features are critical.
Reference
- Attention Is All You Need
- An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale (ViT)
- SlowFast Networks for Video Recognition
- Training data-efficient image transformers & distillation through attention (DeiT)
- Is Space-Time Attention All You Need for Video Understanding? (TimeSformer)
- ViViT: A Video Vision Transformer
- https://sh-tsang.medium.com/review-mvit-multiscale-vision-transformers-656e6fae4a48

Leave a Reply