

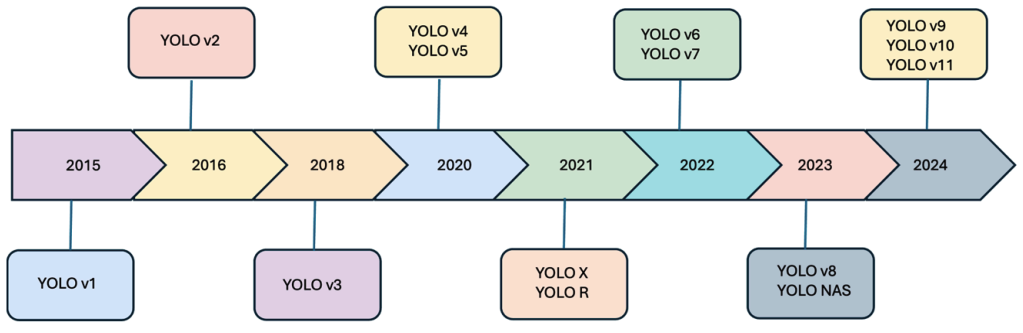
This aims to provide a comprehensive review of the YOLO (You Only Look Once) framework, tracing its evolution up to the latest version, YOLOv11. The goal is to analyze architectural improvements, evaluate performance on benchmarks, survey its applications, and identify research gaps for future work.
Introduction
Motivation
There is a growing demand for object detection algorithms that are both fast and accurate for real-time applications.
Two-stage detectors, while precise, are often too slow for tasks like autonomous driving or live surveillance.
Objective
This aims to provide a comprehensive review of the YOLO (You Only Look Once) frameworks.
YOLO is a single-stage object detector. It reframes object detection as a single regression problem, directly predicting bounding boxes and class probabilities from an image in one pass.
Overall Framework
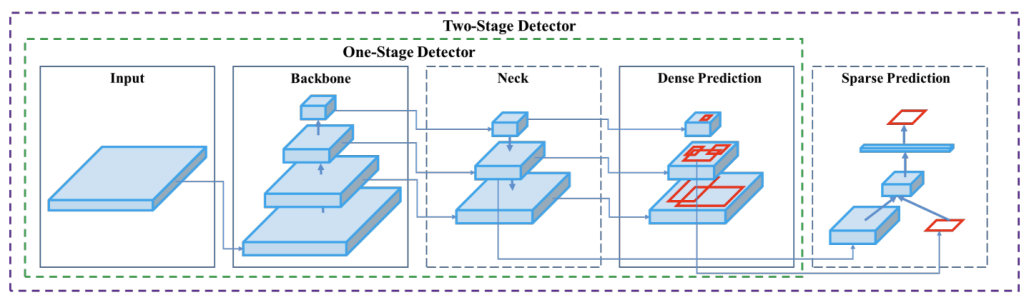
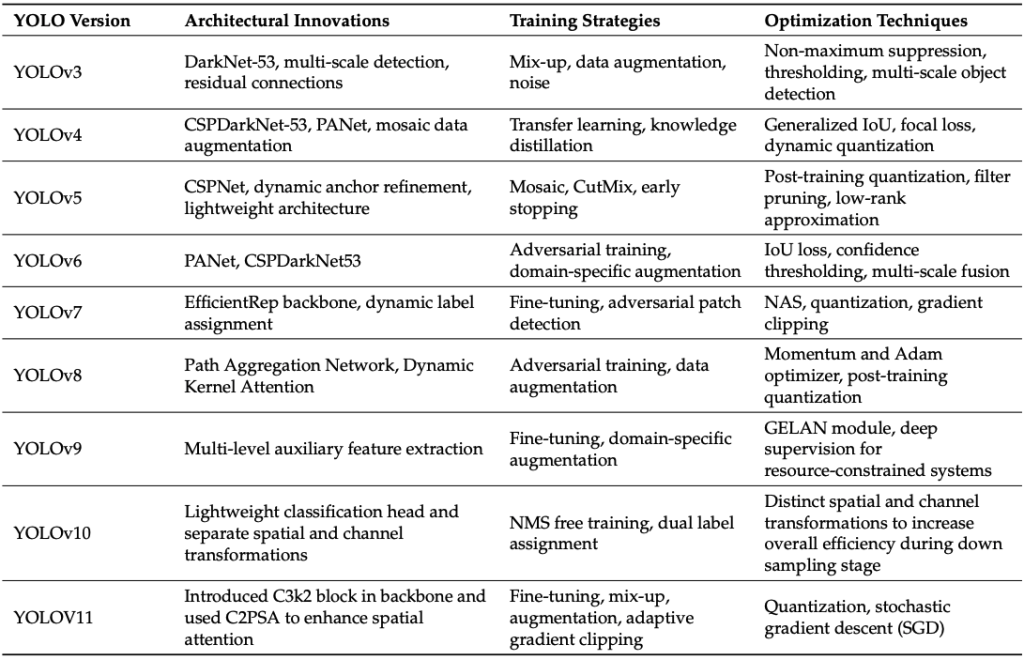
YOLO’s architecture generally consists of three parts:
- Backbone: A pre-trained Convolutional Neural Network (CNN) that extracts feature maps from the input image. Common backbones include DarkNet, CSPDarkNet, and ResNet.
- Neck: Aggregates and refines features from the backbone, often using structures like Feature Pyramid Networks (FPN) or Path Aggregation Networks (PANet) to combine features from different scales, enhancing detection of various-sized objects.
- Head: The detection component that takes the fused features from the neck and makes the final predictions for bounding boxes, objectness scores, and class probabilities.
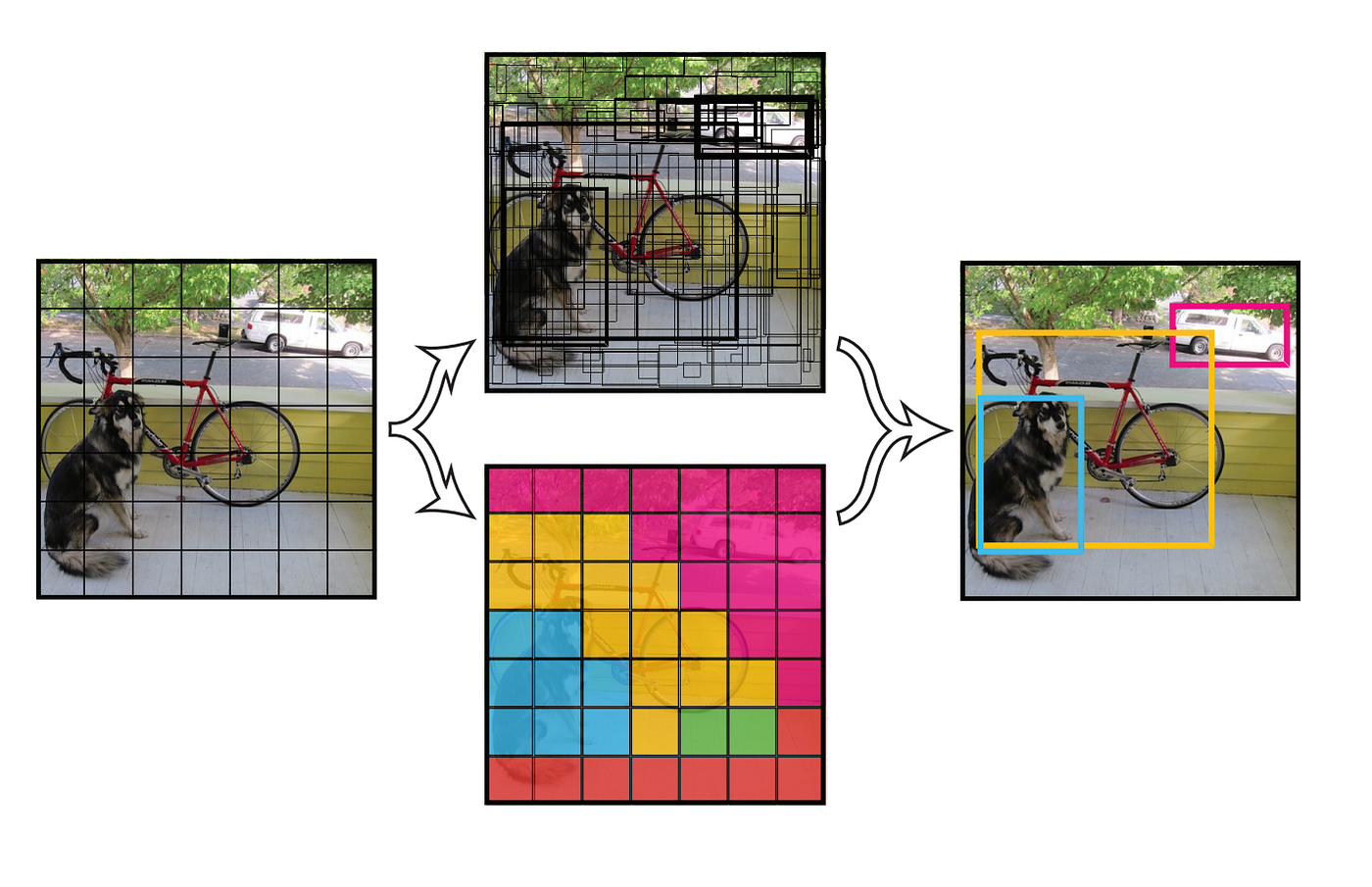
To quickly and accurately identify objects, YOLO divides an image into a grid and predicts both bounding boxes and class probabilities simultaneously. Bounding box coordinates and class probabilities are generated by convolutional layers, following feature extraction by a deep Convolutional Neural Network (CNN).
YOLO improves the detection of objects at varying sizes using anchor boxes at multiple scales. The final detections are refined using Non-Maximum Suppression (NMS), which filters out redundant and low-confidence predictions, making YOLO a highly efficient and reliable method for object detection.
Loss Function
The overall loss is a weighted sum of three components: localization loss (bounding box regression), confidence loss (objectness), and classification loss.
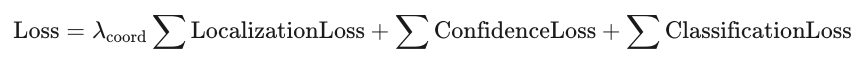
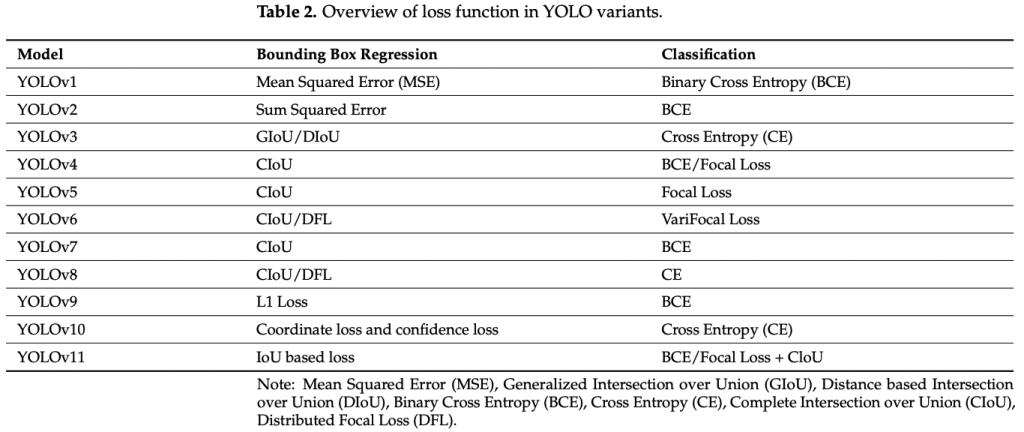
Details
YOLOv1: Unified Real-time Object Detection
The first version marked a paradigm shift by framing object detection as a single regression problem. It used a single-stage, fully end-to-end architecture to achieve real-time speeds (45 FPS on PASCAL VOC 2007) but had limitations in localizing small objects and lower accuracy compared to two-stage models.
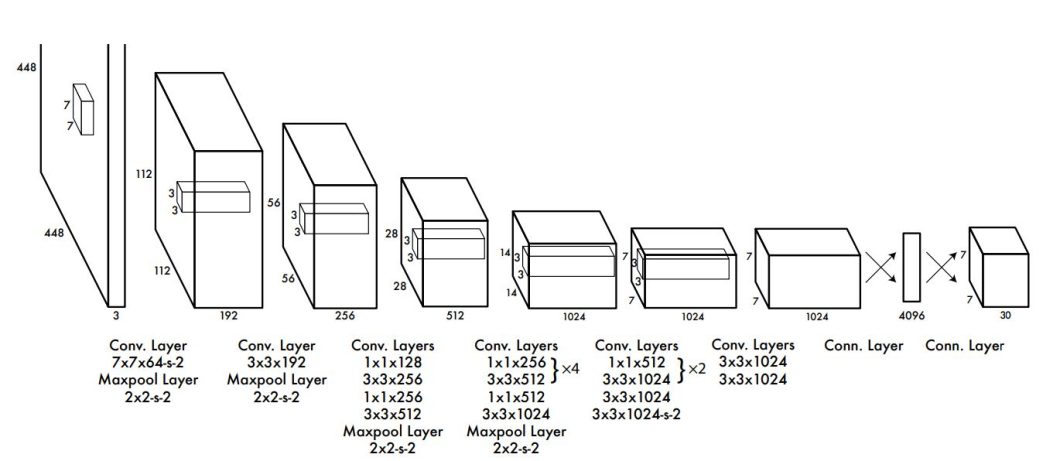
The input image is divided into an S×S grid (with S = 7), where each grid cell is responsible for detecting objects whose centers fall within the cell. Each grid cell predicts B = 2 bounding boxes, associated confidence scores, and C class probabilities.
- Backbone: Inspired by the GoogLeNet (24 convolutional layers followed by 2 fully connected layers).
- Loss Function: Multi-part loss function (localization loss, confidence loss, and classification loss)
Performance: 63,4% mAP at 45 FPS on PASCAL VOC 2007.
YOLOv2: Better, Faster, Stronger (YOLO9000)

This version improved accuracy and recall by introducing anchor boxes, batch normalization, and multi-scale training. A key innovation was its ability to detect over 9,000 object categories through a novel joint training mechanism on detection and classification datasets.
- Backbone: Darknet-19
- Batch Normalization: The inclusion of batch normalization after each convolutional layer improved convergence speed and regularization.
- High-resolution Classifier Pretraining: The classification backbone was pretrained at a higer resolution (448×448 pixels), enhancing its ability to capture fine-grained features.
- Anchor Type: Anchor-based (Pre-defined anchor boxes using K-means).
- Multi-Scale Training: The network changed the input resolution every few iterations (320×320 to 608×608) during training process.
- YOLO9000: A novel hierarchical joint training approach allowed the network to simultaneously learn from both detection dataset (COCO) and classification dataset (ImageNet) enabling the model to have the ability to detect across more than 9000 object categories.
Performance: 76.8% mAP on PASCAL VOC 2007 while running at 67 FPS.
YOLOv3: An Incremental Improvement
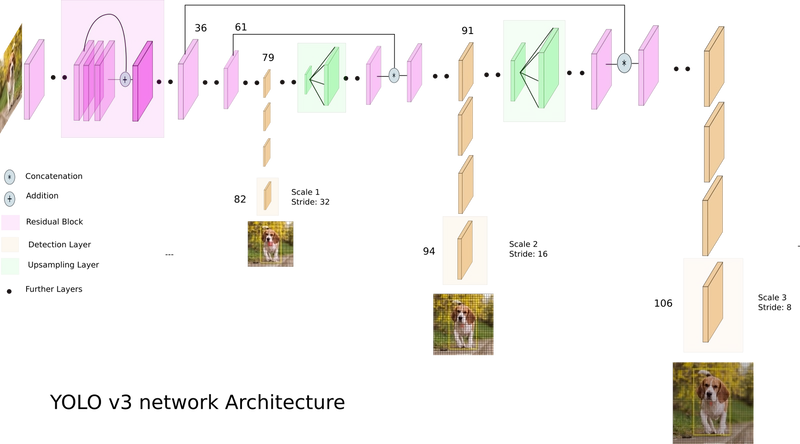
This version delivered incremental improvements, focusing on better detection of small objects.
- Backbone: Darknet-53 (53 convolutional layers with residual connections).
- Anchor Type: Anchor-based (Applying anchor boxes across multiple scales and predicting offsets relative to each anchor box).
- Multi-Scale Feature Prediction: YOLOv3 made predictions at three distinct feature map resolutions.
- Independent Class Predictions: YOLOv3 moved away from using a softmax function over class labels and instead adopted independent logistic classifiers for each class.
- Binary Cross-Entropy Loss: The model employed binary cross-entropy loss for both class probabilities and objectness scores.
Performance: 57.9% mAP at an IoU threshold of 0.5 ([email protected]) on the COCO dataset, while maintaining real-time inference speeds of approximately 30–45 FPS.
YOLOv4: Optimal Speed and accuracy of object detection
Represented a major leap by integrating a “Bag of Freebies” (BoF) and “Bag of Specials” (BoS) to optimize the training process and architecture.
- Backbone: CSPDarknet-53
- Neck: PANet + SPP
- Anchor Type: Anchor-based.
- Data Augmentations: Mosaic and CutMix
Performance: 43.5% AP on the COCO dataset at ~65 FPS.
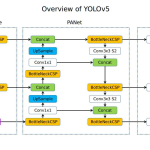
YOLOv5: Practically and Engineering Optimization
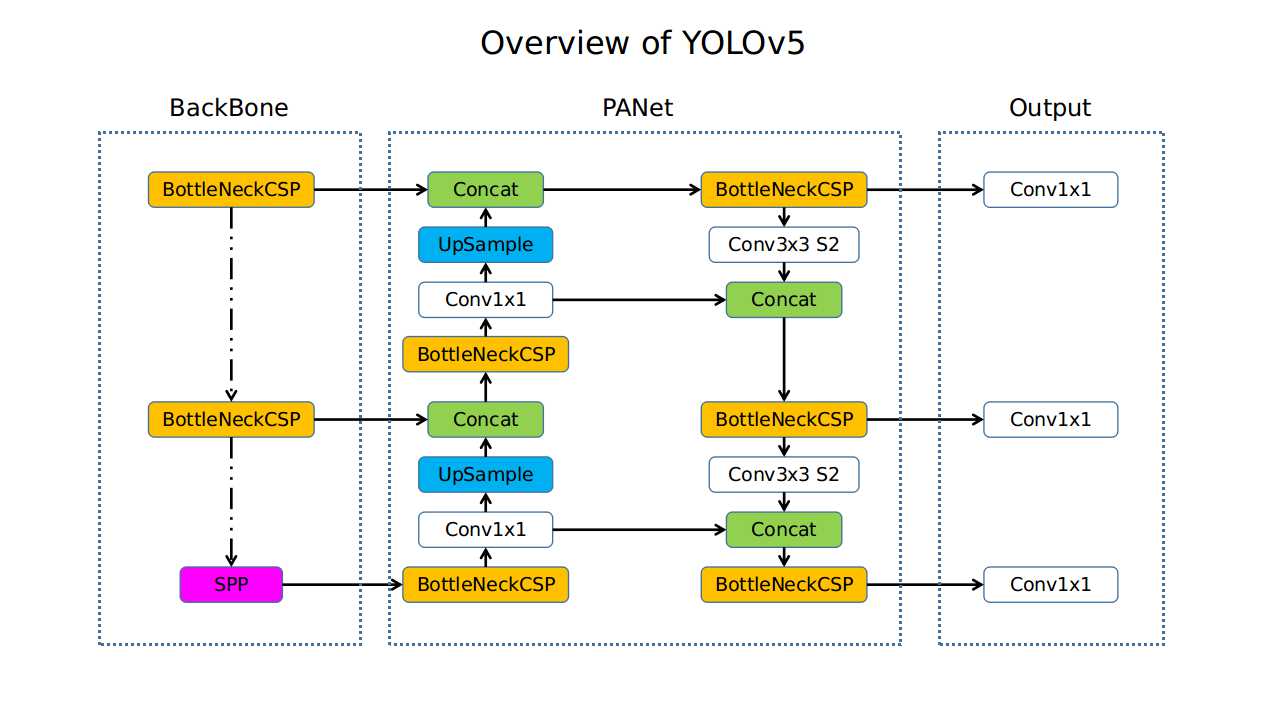
Released by Ultralytics, this version focused on practicality, usability, and engineering efficiency.
- Backbone: CSPDarknet.
- Neck: PANet.
- Anchor Type: Auto Anchor.
- Hyperparameter evolution.
- Easy cross-platform exportability.
- Scalable model variants: YOLOv5s, YOLOv5m, YOLOv5l.
Performance: 50.1% mAP at >60 FPS.
YOLOv6: A High-performance detector for industrial applications
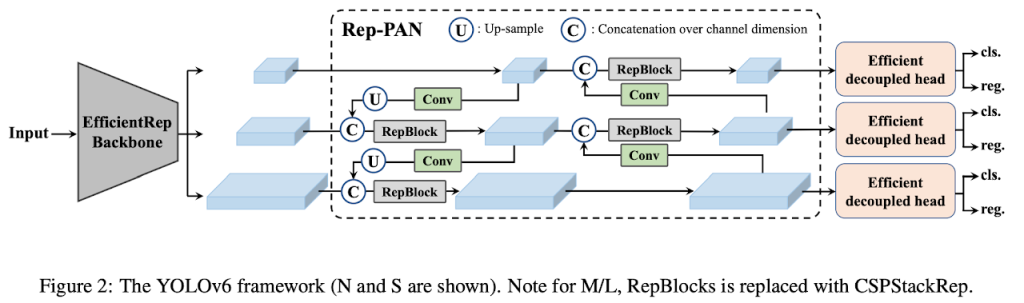
Developed by Meituan for industrial applications.
- Backbone: EfficientRepNet.
- Neck: RepPAN.
- Decoupled head: Separate classification and regression tasks.
- Anchor Type: Hybrid (both anchor-based and anchor-free paradigms).
- Re-parameterization techniques: optimize inference speed.
Performance: 52.5% mAP at >70FPS.
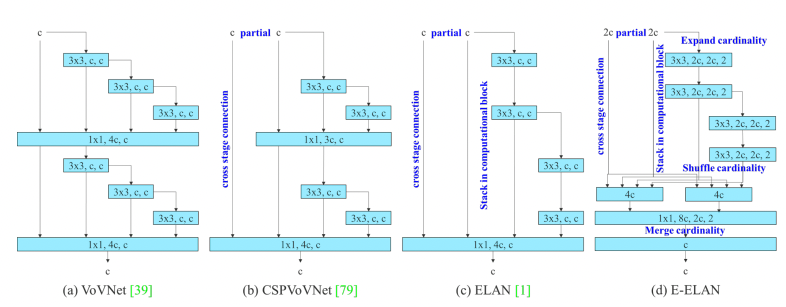
YOLOv7: Extending efficient layer aggregation

This version introduced significant architectural enhancements, including Extended Efficient Layer Aggregation Networks (E-ELAN), which allowed for deeper, more effective networks without disrupting gradient flow.
- Backbone: E-ELAN
- Neck: PANet + E-ELAN
- Anchor Type: Anchor-based
- RepConv:
- Coarse-to-fine head:
Performance: 56.9% mAP at >56 FPS.
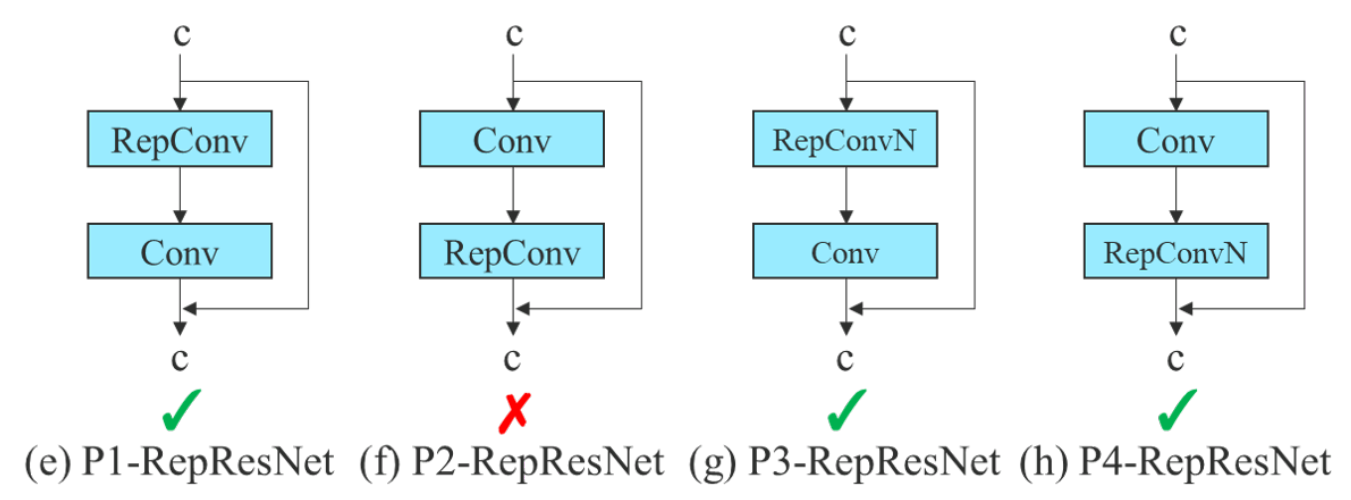
YOLOv8: Anchor-free detection and architecture simplification
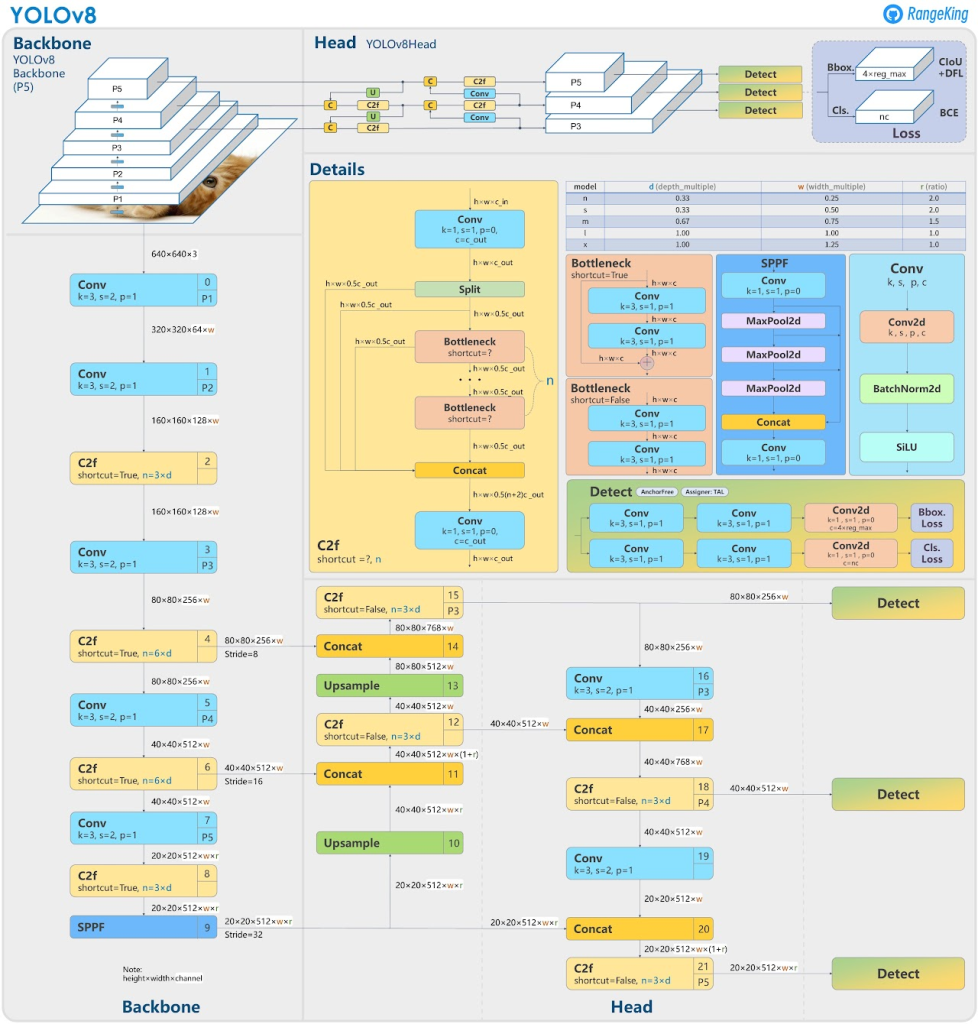
Marked a major shift by adopting a fully anchor-free detection paradigm and a redesigned, simplified head. Developed by Ultralytics, it was designed as a unified framework supporting multiple tasks like instance segmentation and pose estimation with minimal architectural changes.
- Backbone: CSP-C2f
- Head: Decoupled head and Delete the objectness branch.
- Anchor Type: Anchor-free
- Training approach: Task Alignment Learning (TAL)
- Loss Function:
- Detection: CIoU and DFL.
- Classification: BCE.
Performance: ~53% AP on COCO at 60–80 FPS
YOLOv9: generalized efficient layer aggregator for detection

This introduced Generalized Efficient Layer Aggregation Networks (GELAN) to enhance feature reuse and gradient propagation. It also refined the decoupled head and adopted advanced training strategies like Distribution Focal Loss v2 (DFL v2) and an improved SimOTA label assignment.
- Generalized Efficient Layer Aggregation Network (GELAN): A highly flexible and efficient network architecture inspired by CSPNet and ELAN.
- Programmable Gradient Information (PGI): Solves information loss in deep networks by better managing gradient flow.
Performance: YOLOv9-L model achieves over 56% AP on COCO at 50-60 FPS.
YOLOv10: Real-Time End-to-End Object Detection
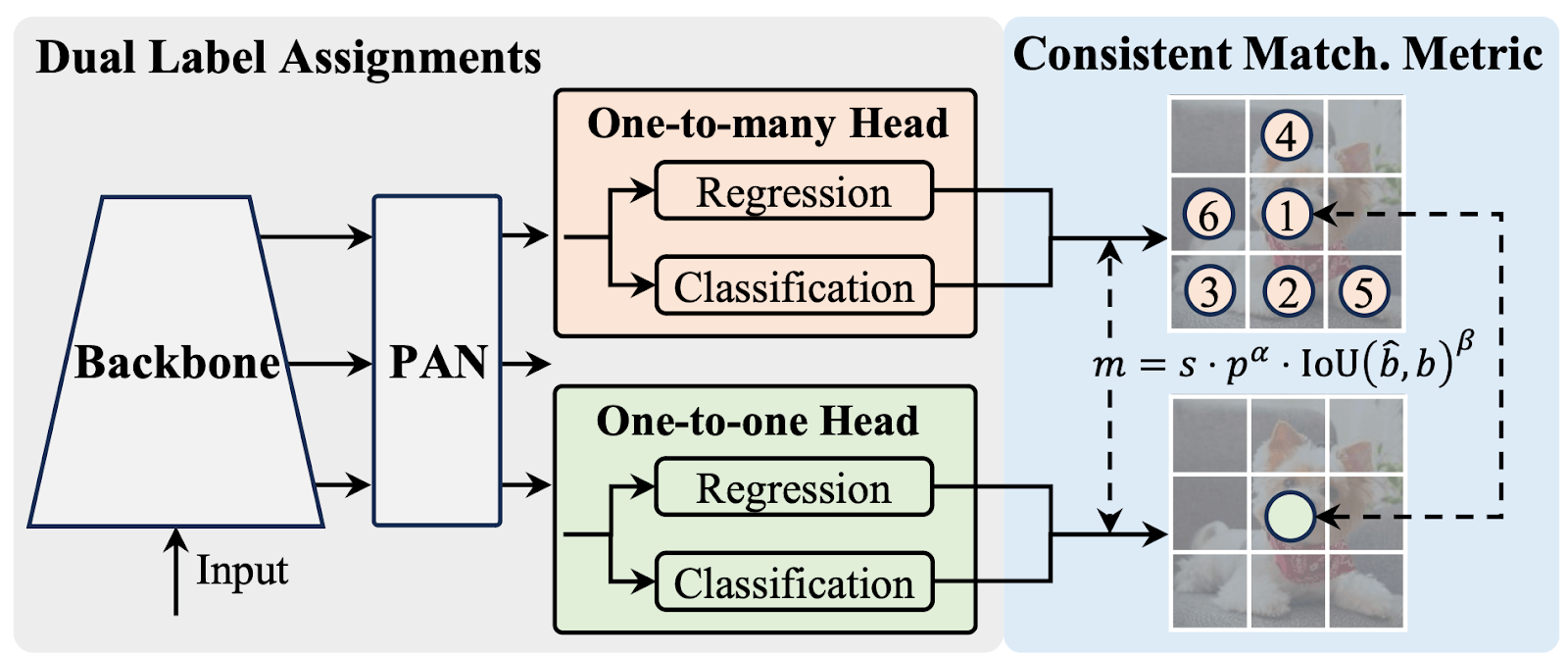
YOLOv10 introduces NMS-free training, which reduces post-processing latency.
Introduced the C3k2 block, enhancing feature aggregation while reducing computational overhead.
YOLOv11: An Overview of the Key Architectural Enhancements
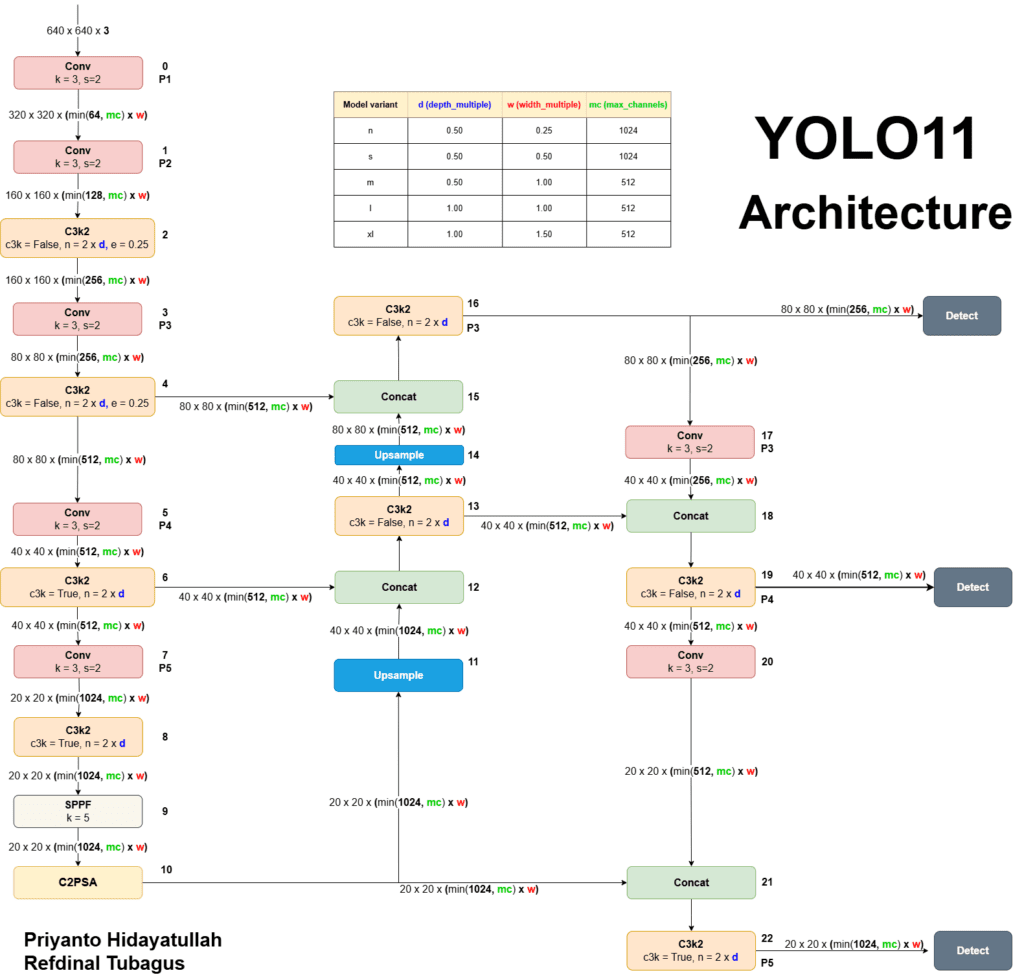
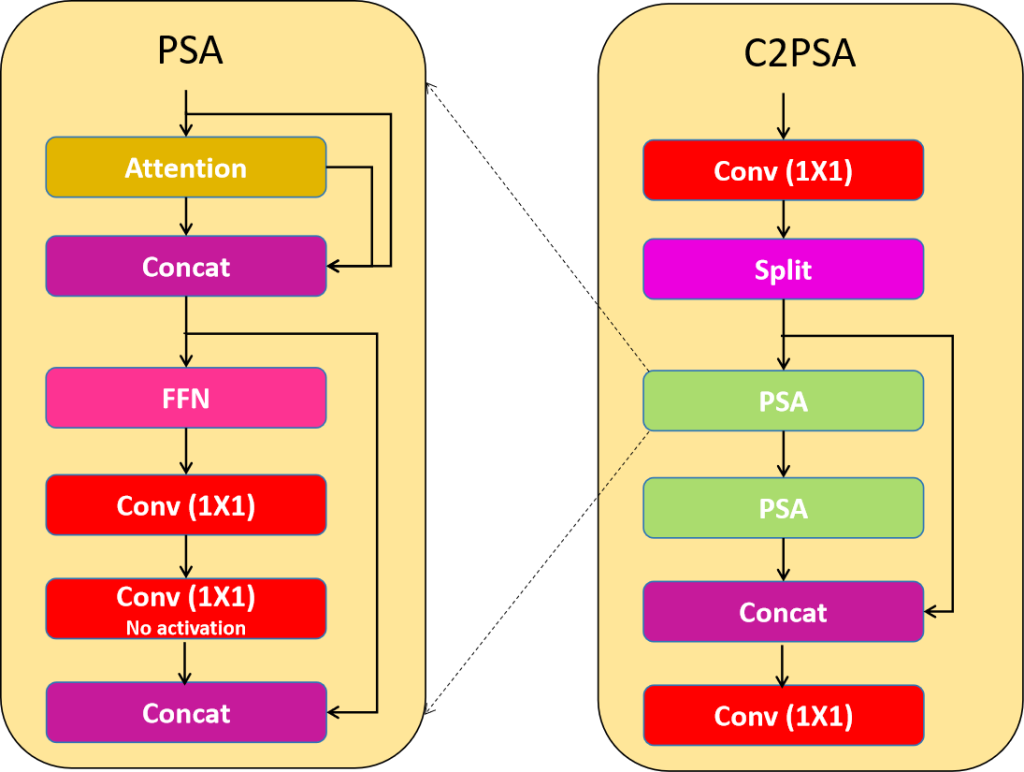
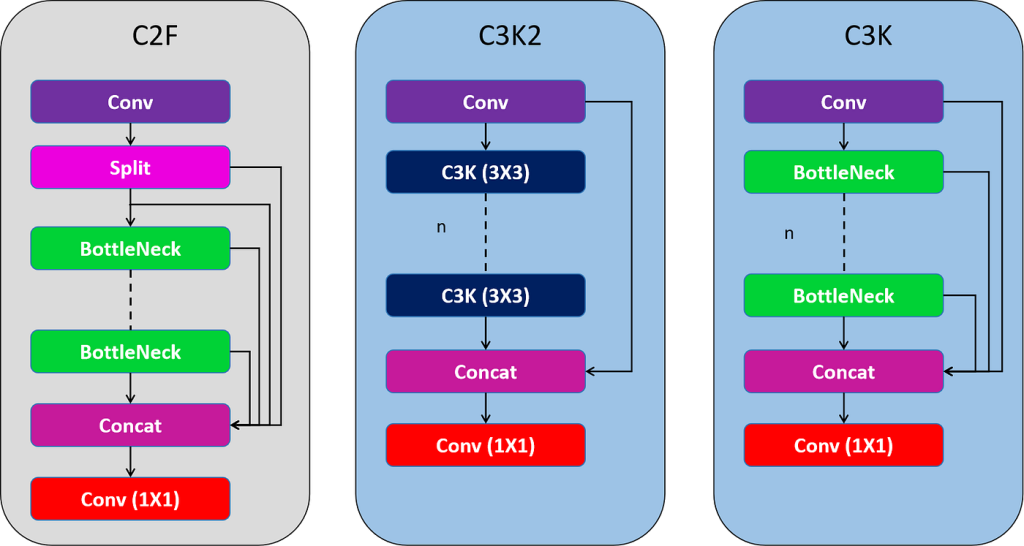
YOLOv11 further enhances accuracy and efficiency with an improved backbone and broader multi-task versatility, including support for object detection, segmentation, classification, and pose estimation.
Introduced C2PSA (Cross-Stage Partial with Spatial Attention) blocks to significantly improve the model’s spatial awareness and focus on critical image regions.
YOLOv12: Attention-Centric Real-Time Object Detectors
YOLOv12 is a new object detection model that successfully integrates attention mechanisms into the traditionally CNN-based YOLO framework. Its primary goal is to leverage the performance benefits of attention without sacrificing the real-time inference speeds that YOLO is known for.
Key improvements:
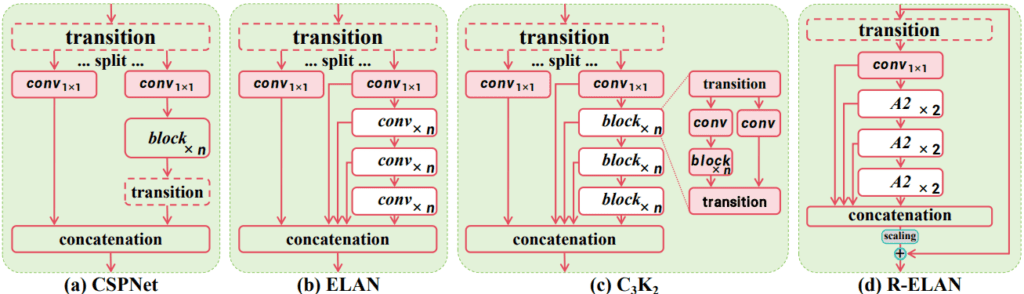
- Area Attention (A2) Module: To overcome the computational cost of traditional attention, YOLOv12 uses an efficient Area Attention module. This module divides the feature map into segments, which reduces computational complexity while still maintaining a large receptive field for the model to work with.
- Residual Efficient Layer Aggregation Networks (R-ELAN): The integration of attention mechanisms created optimization challenges in older architectures. YOLOv12 addresses this with R-ELAN, which improves upon the previous ELAN structure by adding block-level residual connections and scaling techniques. This ensures stable training and improves the model’s performance.
- Architectural Improvements: Several other enhancements were made to boost efficiency:
- Reduced Block Depth: The number of stacked blocks in the final stage of the backbone is reduced to simplify optimization and increase inference speed.
- Flash Attention: Integrates Flash Attention to optimize memory access operations, which is a major bottleneck in standard attention mechanisms.
- Removal of Positional Encoding: Positional encoding is eliminated to make the model faster and simpler without any performance loss.
- Adjusted MLP Ratio: The expansion ratio of the Multi-Layer Perceptron (MLP) is reduced from 4 to 1.2 to better balance the computational load between attention and feed-forward networks.
Reference
- The YOLO Framework: A Comprehensive Review of Evolution, Applications, and Benchmarks in Object Detection
- YOLOv1 to YOLOv11: A Comprehensive Survey of Real-Time Object Detection Innovations and Challenges
- A Review of YOLOv12: Attention-Based Enhancements vs. Previous Versions

Leave a Reply