

Introduction
Objective
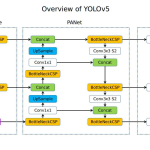
YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics.
Framework

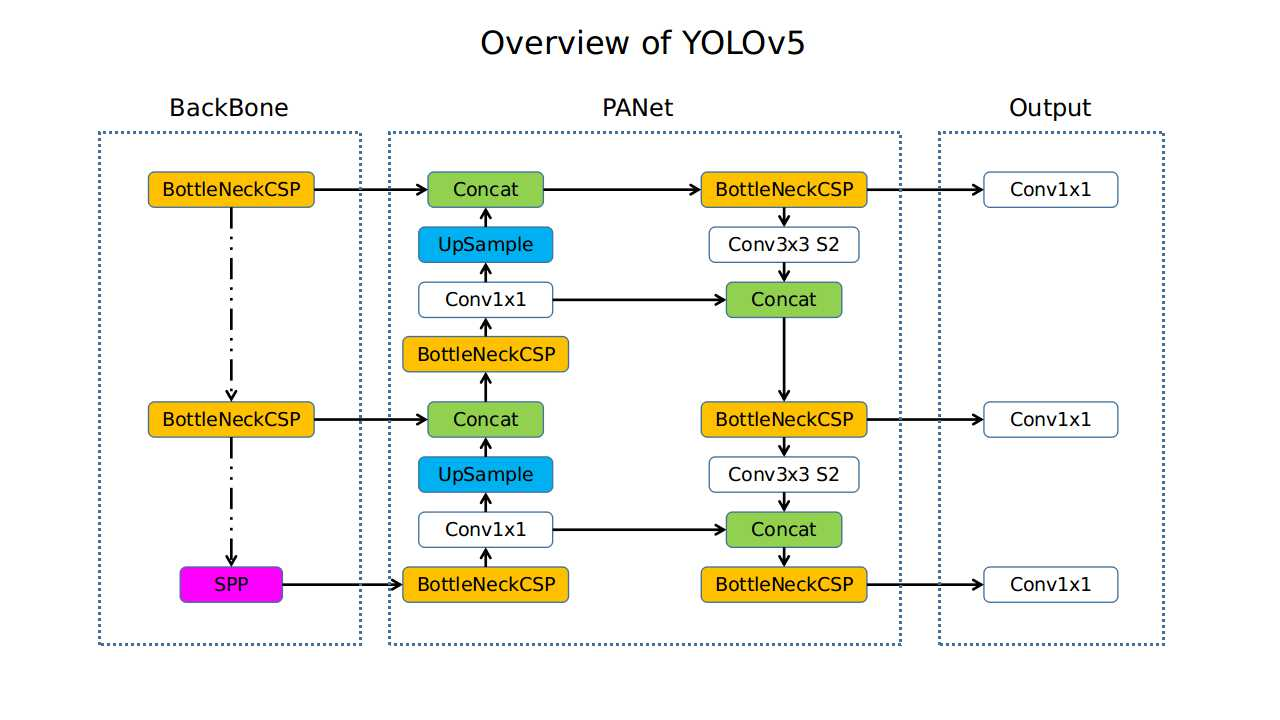
- Backbone:
- CSPDarkNet53.
- Focus layer is replaced by a 6×6 Conv2d.
- Later versions (v6.0 and onward) utilize the C3 module, which is a more compact and efficient implementation of the CSP concept. The C3 module, composed of three convolutional layers and a series of bottleneck blocks, is a fundamental component that contributes to the backbone’s balance of performance and computational efficiency.
- Neck: SPPF – Spatial Pyramid Pooling – Fast.
- SPPF provides a multi-scale representation of the input feature maps.
- By pooling at different scales, SPPF allows the model to capture features at various levels of abstraction.
- SPPF does not produce a fixed-length output vector as in the SPPNet but instead concatenates features from max-pooling layers with different kernel sizes to preserve spatial dimensions.

- Head: Anchor-Based YOLOv3 Prediction Layer.
Contribution
A defining contribution of YOLOv5 was its native implementation within the PyTorch framework.
Ultralytics provides a family of pre-configured models—YOLOv5n (nano), YOLOv5s (small), YOLOv5m (medium), YOLOv5l (large), and YOLOv5x (extra-large)—that all share the same underlying architecture but vary in size and computational complexity.
Details
Data Augmentation
- Mosaic.
- Copy-Paste.
- Mixup.
- HSV augmentation.
- Random Horizontal Flip
Bounding Box coordinates Prediction
In previous YOLO, the box coordinates were directly predicted using the an exp() function, this was a “serious claw” because the exponential in unbounded.
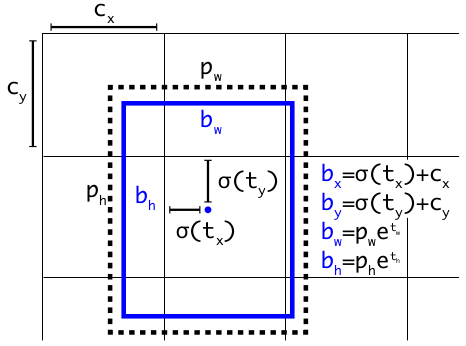
In YOLOv5, the formula has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box. It “patched” the formulas to ensure all outputs are constrained within a sensible range using the sigmoid function, σ(x), which always outputs a value between 0 and 1.
Center Point Prediction (bx, by)
t_x,t_y: These are the raw outputs from the network layer.σ(): The sigmoid function squishes the raw outputs into the range(0, 1).2σ(t) - 0.5: This scales and shifts the range from(0, 1)to(-0.5, 1.5). This allows the object’s center point to be predicted slightly outside of its responsible grid cell, offering more flexibility in localization.c_x,c_y: These are the coordinates of the top-left corner of the grid cell, making the prediction relative to the grid.
Width and Height Prediction (bw, bh)
t_w,t_h: The raw outputs from the network for scaling.p_w,p_h: The width and height of the pre-defined anchor box.(2σ(t))2: This is the key to stability.- The sigmoid
σ(t)produces a value in(0, 1). - Multiplying by 2,
2σ(t), scales the range to(0, 2). - Squaring it,
(2σ(t))^2, results in a final scaling factor in the range(0, 4).
This means the predicted width (b_w) and height (b_h) are calculated by scaling the anchor dimensions (p_w, p_h) by a factor that is strictly bounded between 0 and 4.
Comparison
- Compare the center point offset before and after scaling. The center point offset range is adjusted from (0, 1) to (-0.5, 1.5). Therefore, offset can easily get 0 or 1.

- Compare the height and width scaling ratio (relative to anchor) before and after adjustment. The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training.

Auto Anchor
AutoAnchor mechanism automates the selection of optimal anchor boxes for a given dataset. It analyzes the statistical distribution of ground truth bounding box shapes and sizes within the user’s custom dataset.
Method:
- Employs a k-means clustering algorithm to group these ground truth boxes and identify the most representative shapes to serve as anchors.
- This process is further refined using a genetic algorithm to evolve the anchor set towards configurations that maximize recall with the ground truth boxes.
This ensures that the anchor priors are tailored specifically to the objects the model is being trained to detect, which can significantly improve the accuracy of bounding box regression.
Build Targets
The build target process in YOLOv5 is critical for training efficiency and model accuracy. It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
Process:
- Calculate the ratio of the ground truth box dimensions and the dimensions of each anchor template.

- If the calculated ratio is within the threshold, match the ground truth box with the corresponding anchor.

- Assign the matched anchor to the appropriate cells, keeping in mind that due to the revised center point offset, a ground truth box can be assigned to more than one anchor. Because the center point offset range is adjusted from (0, 1) to (-0.5, 1.5). GT Box can be assigned to more anchors.

- This way, the build targets process ensures that each ground truth object is properly assigned and matched during the training process, allowing YOLOv5 to learn the task of object detection more effectively.
Loss Function
The loss in YOLOv5 is computed as a combination of three individual loss components:
- Classes Loss (BCE Loss): Binary Cross-Entropy loss, measures the error for the classification task.
- Objectness Loss (BCE Loss): Another Binary Cross-Entropy loss, calculates the error in detecting whether an object is present in a particular grid cell or not.
- Location Loss (CIoU Loss): Complete IoU loss, measures the error in localizing the object within the grid cell.
The balance weights are [4.0, 1.0, 0.4] respectively.
Training Strategies
- Multiscale Training: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
- AutoAnchor: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
- Warmup and Cosine LR Scheduler: A method to adjust the learning rate to enhance model performance.
- Exponential Moving Average (EMA): A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
- Mixed Precision Training: A method to perform operations in half-precision format, reducing memory usage and enhancing computational speed.
- Hyperparameter Evolution: A strategy to automatically tune hyperparameters to achieve optimal performance. Learn more about hyperparameter tuning.
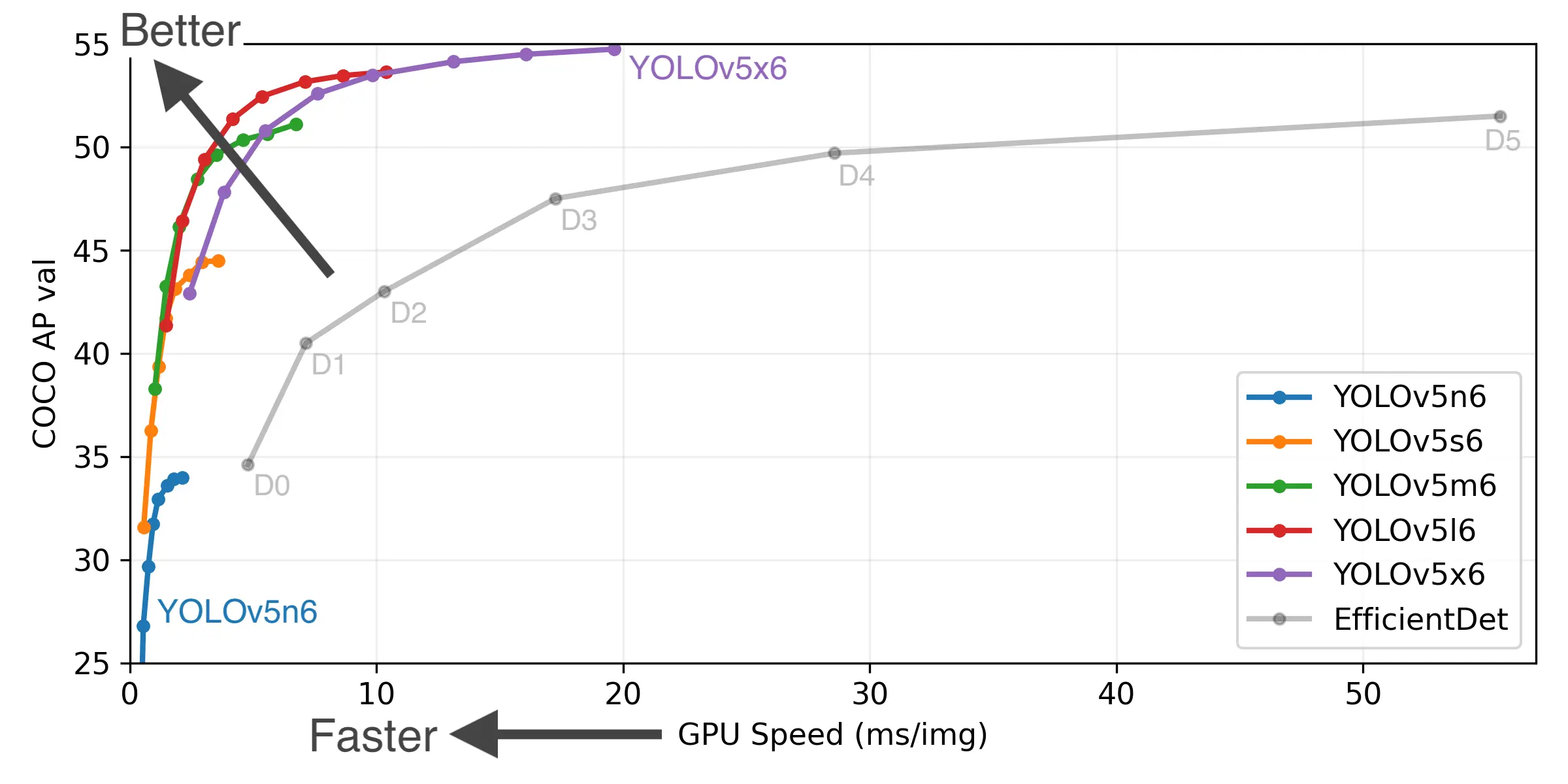
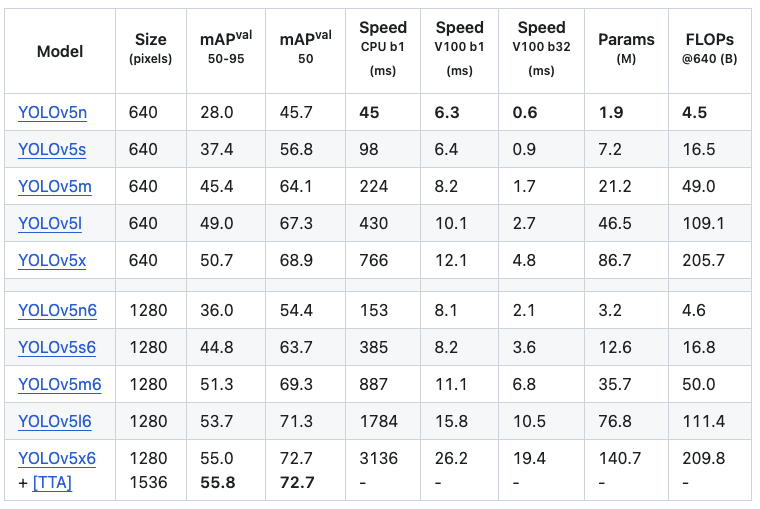
Experimental Results
COCO Detection
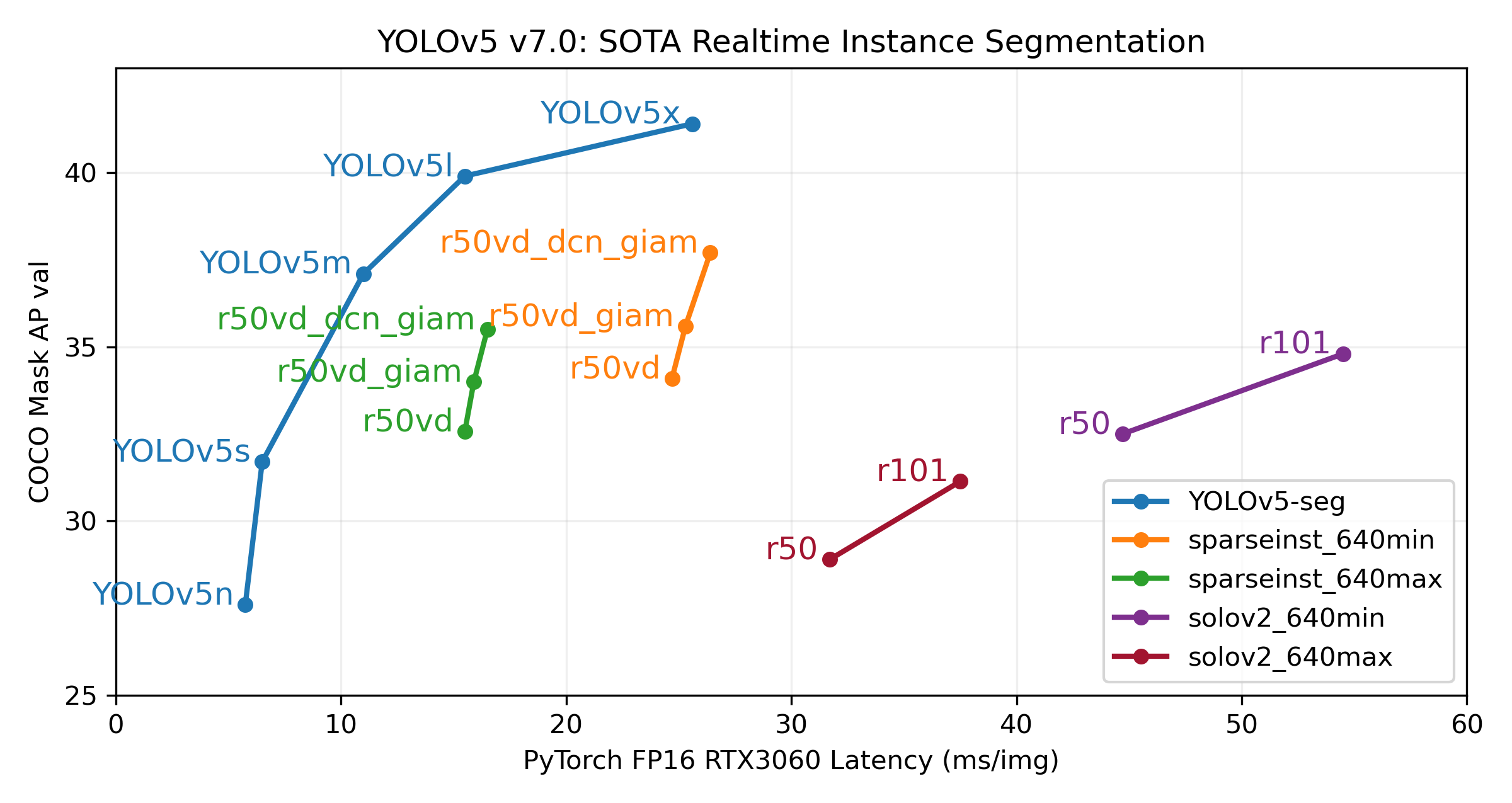
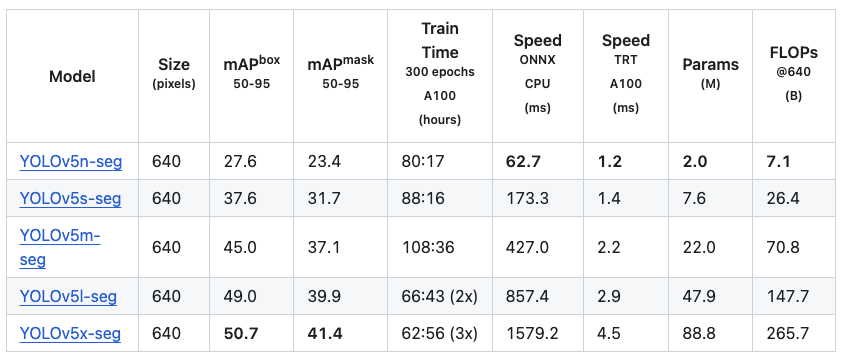
Segmentation
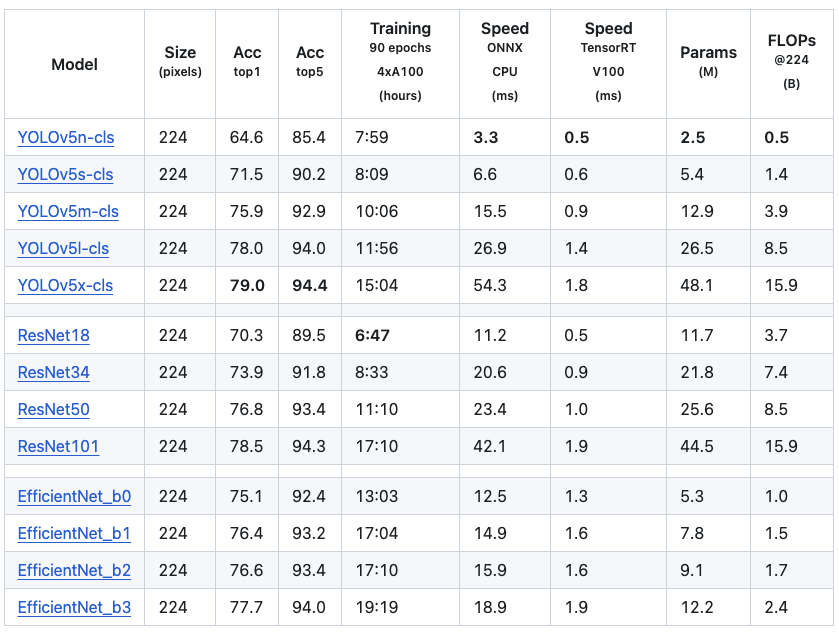
Classification
future work
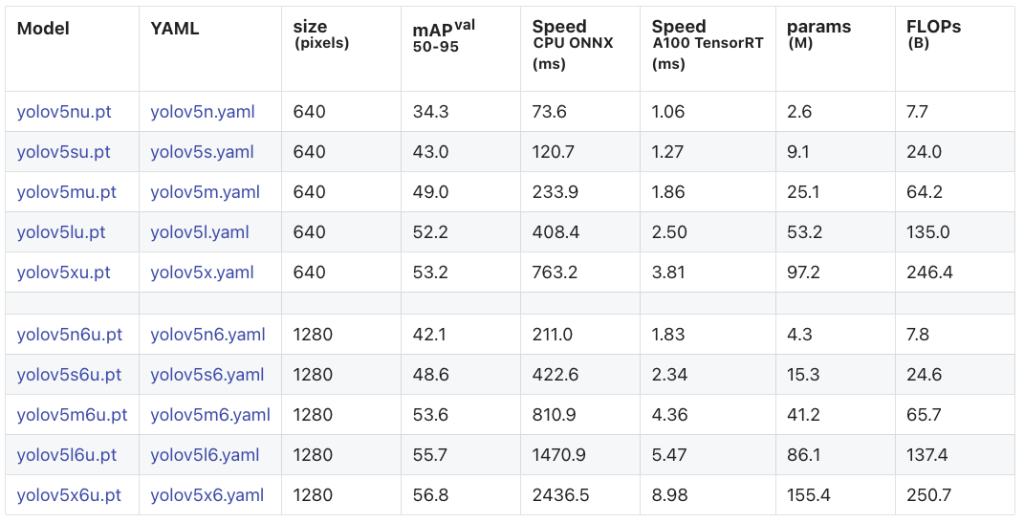
YOLOv5u: A Bridge to Anchor-Free Architectures
- Ultralytics YOLOv5u is an advanced version of YOLOv5, integrating the anchor-free, objectness-free split head that enhances the accuracy-speed tradeoff for real-time object detection tasks.
- Anchor-free Split Ultralytics Head: Traditional object detection models rely on predefined anchor boxes to predict object locations. However, YOLOv5u modernizes this approach. By adopting an anchor-free split Ultralytics head, it ensures a more flexible and adaptive detection mechanism, consequently enhancing the performance in diverse scenarios.
- Optimized Accuracy-Speed Tradeoff: Speed and accuracy often pull in opposite directions. But YOLOv5u challenges this tradeoff. It offers a calibrated balance, ensuring real-time detections without compromising on accuracy.
- Variety of Pre-trained Models: Understanding that different tasks require different toolsets, YOLOv5u provides a plethora of pre-trained models. Whether you’re focusing on Inference, Validation, or Training, there’s a tailor-made model awaiting you. This variety ensures you’re not just using a one-size-fits-all solution, but a model specifically fine-tuned for your unique challenge.

Leave a Reply